CN111538913B - A personalized recommendation method for AIDS prevention and control knowledge education - Google Patents
A personalized recommendation method for AIDS prevention and control knowledge education Download PDFInfo
- Publication number
- CN111538913B CN111538913B CN202010336906.6A CN202010336906A CN111538913B CN 111538913 B CN111538913 B CN 111538913B CN 202010336906 A CN202010336906 A CN 202010336906A CN 111538913 B CN111538913 B CN 111538913B
- Authority
- CN
- China
- Prior art keywords
- information
- distance
- users
- center
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 208000030507 AIDS Diseases 0.000 title claims abstract description 34
- 238000000034 method Methods 0.000 title claims abstract description 25
- 230000002265 prevention Effects 0.000 title claims abstract description 21
- 238000004364 calculation method Methods 0.000 claims description 11
- 230000008569 process Effects 0.000 claims description 3
- 238000001914 filtration Methods 0.000 description 8
- 230000006399 behavior Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 208000035473 Communicable disease Diseases 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000000586 desensitisation Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000011524 similarity measure Methods 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9536—Search customisation based on social or collaborative filtering
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/906—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开一种艾滋病防控知识宣教的个性化推荐方法,应用于大数据处理领域,针对现有技术的推荐结果精准性不高的问题,本发明在协同过滤推荐算法基础上,利用KL散度解决由于数据稀疏性导致不同维度数据不能利用的问题,有效处理了传统推荐算法的数据稀疏性问题;在选择聚类中心时有效地区分不同的宣教内容,同时,距离模型打破了经典几何距离方法(如欧几里德距离)的对称模式,并考虑了宣教内容之间不同评级数的影响,以强调其不对称关系,相比于现有技术可提高推荐精准性。

The invention discloses a personalized recommendation method for AIDS prevention and control knowledge publicity and education, which is applied in the field of big data processing. Aiming at the problem of low accuracy of the recommendation results in the prior art, the invention uses KL scattered It solves the problem that data of different dimensions cannot be used due to data sparsity, and effectively handles the data sparsity problem of traditional recommendation algorithms; effectively distinguishes different missionary content when selecting cluster centers, and at the same time, the distance model breaks the classic geometric distance The symmetric mode of the method (such as Euclidean distance) and the impact of different ratings between missionary content are considered to emphasize its asymmetric relationship, which can improve the accuracy of recommendation compared with the existing technology.
Description
技术领域technical field
本发明属于大数据处理领域,特别涉及一种艾滋病防控知识的个性化推荐技术。The invention belongs to the field of big data processing, and in particular relates to a personalized recommendation technology for AIDS prevention and control knowledge.
背景技术Background technique
艾滋病作为一种目前无法治愈的慢性传染疾病,防治艾滋病任重道远。普通大众对艾滋病相关知识了解薄弱,而目前获取艾滋病健康知识的途径主要由相关部门不定期组织现场宣讲及发放宣传资料,或者借助电视广播等传统媒体,这些方式对民众而言都是被动接收,且难以跟踪学习情况。因此,艾滋病防控知识宣传需要更多的宣传手段及推广力度。As a chronic infectious disease that cannot be cured at present, AIDS has a long way to go. The general public has a weak understanding of AIDS-related knowledge, and the current way to obtain AIDS health knowledge is mainly through on-site lectures organized by relevant departments and distribution of promotional materials from time to time, or through traditional media such as TV broadcasts. These methods are passive reception for the public. and difficult to track learning. Therefore, the publicity of AIDS prevention and control knowledge needs more publicity means and efforts.
随着智能手机的普及,可以通过手机推送艾滋防控相关的文章、视频等,还可通过答题等方式检验用户学习效果,用户可随时主动获取相关宣教信息,极大地扩大宣教工作覆盖的人群范围。智能手机还可记录用户查看宣教信息的行为及相关知识掌握情况,个性化推荐不同主题的文章、视频和答题知识点,一方面提高用户学习兴趣,另一方面可跟踪用户依从性,为相关部门进一步指导工作提供参考依据。With the popularization of smartphones, articles and videos related to AIDS prevention and control can be pushed through mobile phones, and users’ learning effects can also be tested by answering questions. Users can actively obtain relevant missionary information at any time, greatly expanding the scope of people covered by missionary work . Smartphones can also record users’ behaviors of viewing missionary information and their mastery of related knowledge, and recommend personalized articles, videos, and knowledge points for answering questions on different topics. Provide references for further guidance.
为了满足用户个性化需求,推荐系统(RS)作为一种信息过滤技术广泛用于处理信息过滤问题,从大量数据中识别出用户感兴趣的内容,并将这些内容推荐给用户。协同过滤(CF)算法因其简单和高效而成为最广泛应用的推荐技术之一。协同过滤推荐算法将用户历史行为数据生成推荐项,根据用户之间的相似程度或可选项目之间的相似程度,按相似程度高低推荐给用户。中国专利“CN109977315A一种文章推荐方法、装置、设备及存储介质”根据用户历史浏览文章,通过对预设的栈式降噪自编码器和预设的概率矩阵分解模型进行训练,通过将上一个推荐算法得到的推荐文章列表作为下一个算法的输入,依次执行得到最终推荐文章,以此方法流水线的得到推荐文章列表。此方法较为单一,仅通过用户历史浏览文章信息作为推荐依据。In order to meet the personalized needs of users, the recommender system (RS), as an information filtering technology, is widely used to deal with the problem of information filtering, identifying content that users are interested in from a large amount of data, and recommending these content to users. Collaborative filtering (CF) algorithm is one of the most widely used recommendation techniques due to its simplicity and efficiency. The collaborative filtering recommendation algorithm generates recommended items from user historical behavior data, and recommends them to users according to the similarity between users or the similarity between optional items. Chinese patent "CN109977315A An article recommendation method, device, equipment and storage medium" browses articles according to user history, trains the preset stacked noise reduction autoencoder and the preset probability matrix decomposition model, and passes the previous The list of recommended articles obtained by the recommendation algorithm is used as the input of the next algorithm, and the final recommended articles are obtained by sequential execution. In this way, the list of recommended articles is obtained in a pipeline. This method is relatively simple, and only uses the user's historical browsing article information as the basis for recommendation.
现有技术存在的缺陷:The defective that existing technology exists:
在传统的协同过滤推荐算法中,经常使用经典距离度量(例如欧几里德或曼哈顿距离)来计算两个项目之间的相似度。然而,这些距离方法取决于用于相似性计算的共同评定项目,即用户评定的共同属性,只有包含用户共同评定属性的项目才能用作相似性度量。然而,由于互联网数据普遍存在稀疏性特点,传统的协同过滤方法无法充分利用所有用户评级信息,而只能使用一小部分用户评级数据,这会影响推荐结果的精准性。In traditional collaborative filtering recommendation algorithms, classical distance measures (such as Euclidean or Manhattan distance) are often used to calculate the similarity between two items. However, these distance methods depend on the common-rated items used for similarity computation, that is, common attributes rated by users, and only items containing common-rated attributes by users can be used as similarity measures. However, due to the general sparsity of Internet data, traditional collaborative filtering methods cannot make full use of all user rating information, but can only use a small part of user rating data, which will affect the accuracy of recommendation results.
发明内容Contents of the invention
为解决上述技术问题,本发明提出一种艾滋病防控知识宣教的个性化推荐方法,在协同过滤(CF)推荐算法基础上,基于KL散度(Kullback-Leibler散度,又称信息散度Information Divergence)解决由于数据稀疏性导致不同维度数据不能利用的问题,提高了推荐准确性。In order to solve the above technical problems, the present invention proposes a personalized recommendation method for AIDS prevention and control knowledge education, based on the collaborative filtering (CF) recommendation algorithm, based on KL divergence (Kullback-Leibler divergence, also known as information divergence Information Divergence) solves the problem that data of different dimensions cannot be utilized due to data sparsity, and improves the accuracy of recommendation.
本发明采用的技术方案为:一种艾滋病防控知识宣教的个性化推荐方法,包括:The technical solution adopted in the present invention is: a personalized recommendation method for AIDS prevention and control knowledge education, including:
S1、通过终端设备收集用户个人基础信息,收集用户历史浏览信息;S1. Collect basic personal information of users through terminal equipment, and collect historical browsing information of users;
S2、根据用户历史浏览信息,采用KL散度计算向用户推荐艾滋病防控知识信息。S2. According to the user's historical browsing information, the KL divergence calculation is used to recommend AIDS prevention and control knowledge information to the user.
步骤S2具体为:Step S2 is specifically:
S21、采用KL散度计算任意两信息之间的距离;S21. Using KL divergence to calculate the distance between any two pieces of information;
S22、根据步骤S21计算的两信息之间的距离,从信息概率分布角度找出所有可用信息的k个聚类中心,并生成信息聚类结果;S22. According to the distance between the two pieces of information calculated in step S21, find out k cluster centers of all available information from the perspective of information probability distribution, and generate an information clustering result;
S23、基于Top-n进行信息推荐。S23. Perform information recommendation based on Top-n.
步骤S21的计算式为:The calculation formula of step S21 is:

其中,m是相同类别的信息数量,


步骤S22具体为:Step S22 is specifically:
S221、根据步骤S21计算的两信息之间的距离,基于K-medoids确定聚类中心;S221, according to the distance between the two information calculated in step S21, determine the clustering center based on K-medoids;
S222、根据余下的非中心信息与各中心信息之间的KL距离,对非中心信息进行分类。S222. Classify the non-central information according to the KL distance between the remaining non-central information and each central information.
步骤S23具体为:未评级信息根据其最近邻集合,计算信息在具体用户中的预测评级值;根据具体用户对未评级信息的预测评级值,选择具有最高预测评级值的前n个信息作为推荐列表。Step S23 is specifically as follows: the unrated information calculates the predicted rating value of the information among the specific users according to its nearest neighbor set; according to the predicted rating value of the unrated information by the specific user, select the top n pieces of information with the highest predicted rating value as recommendations list.
所述最近邻集合的计算过程为:对未评级信息,在其所属类中选出与该信息KL距离最近的n个信息,将这n个信息作为该信息的最近邻集合。The calculation process of the nearest neighbor set is as follows: for unrated information, select n pieces of information in the class to which the information is the closest to KL, and use these n pieces of information as the nearest neighbor set of the information.
步骤S2初始未采集用户历史浏览信息时,推荐最新的信息;当信息浏览量大于第一阈值,且信息浏览量大于第一阈值的信息数量大于n,则向用户推荐浏览量最高的n个信息;否则推荐最新的信息。Step S2 When the user’s historical browsing information is not initially collected, recommend the latest information; when the amount of information viewed is greater than the first threshold, and the number of information with the amount of information viewed greater than the first threshold is greater than n, recommend the n pieces of information with the highest amount of browsing to the user ; otherwise recommend the latest information.
步骤S1所述信息包括文章或视频。The information in step S1 includes articles or videos.
步骤S1中的终端设备为智能手机、PC、平板。The terminal devices in step S1 are smartphones, PCs, and tablets.
还包括根据用户对获取艾滋相关信息的感兴趣程度,进行感兴趣信息的补充推送。It also includes supplementary pushing of interested information according to the user's interest in obtaining AIDS-related information.
本发明的有益效果:本发明在协同过滤推荐算法基础上,利用KL散度解决由于数据稀疏性导致不同维度数据不能利用的问题,有效处理了传统推荐算法的数据稀疏性问题;在选择聚类中心时有效地区分不同的宣教内容,同时,距离模型打破了经典几何距离方法(如欧几里德距离)的对称模式,并考虑了宣教内容之间不同评级数的影响,以强调其不对称关系,可提高推荐精准性。Beneficial effects of the present invention: on the basis of the collaborative filtering recommendation algorithm, the present invention uses KL divergence to solve the problem that data in different dimensions cannot be used due to data sparsity, and effectively handles the data sparsity problem of traditional recommendation algorithms; The center time effectively distinguishes different missionary content. At the same time, the distance model breaks the symmetry mode of classical geometric distance methods (such as Euclidean distance), and considers the influence of different rating numbers between missionary content to emphasize its asymmetry relationship, which can improve the accuracy of recommendation.
附图说明Description of drawings
图1为本发明的方案流程图。Fig. 1 is the scheme flowchart of the present invention.
具体实施方式Detailed ways
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。In order to facilitate those skilled in the art to understand the technical content of the present invention, the content of the present invention will be further explained below in conjunction with the accompanying drawings.
图1是本发明技术方案的主流程图,本发明方法的实现过程包括如下步骤:Fig. 1 is the main flowchart of technical solution of the present invention, and the realization process of the inventive method comprises the following steps:
S1.收集用户个人基础信息及用户类别(普通人群、稳健型人群和进取型人群);收集用户历史浏览信息;新用户初始归为普通人群。S1. Collect basic personal information of users and user categories (ordinary people, stable people and aggressive people); collect historical browsing information of users; new users are initially classified as ordinary people.
S2.基于用户历史浏览信息,推荐用户相关及感兴趣的浏览信息。S2. Based on the user's historical browsing information, recommend relevant and interesting browsing information for the user.
S3.对进取型人群推荐更多艾滋防治、艾滋治疗等内容。本实施例中还针对不同的用户对获取艾滋相关信息的感兴趣程度,进行热点艾滋信息推荐。S3. Recommend more content on AIDS prevention and treatment for aggressive people. In this embodiment, according to the degree of interest of different users in acquiring AIDS-related information, hot-spot AIDS information is recommended.
S11.通过智能手机(还可以是PC或平板)应用程序,提供艾滋病相关宣教知识供用户查看学习,通过应用程序获取用户个人基础信息,以及用户对各类艾滋宣教知识的浏览行为信息。S11. Provide AIDS-related publicity and education knowledge for users to view and learn through smart phone (or PC or tablet) applications, and obtain basic personal information of users and users' browsing behavior information on various AIDS publicity and education knowledge through the application.
S12.本方案涉及的手机应用程序提供的艾滋宣传知识包含文章及视频形式,本方案对文章和视频的分类方法相同,推荐方法相同,以下推荐方法以文章推荐为例进行介绍。S12. The AIDS publicity knowledge provided by the mobile apps involved in this program includes articles and videos. This program classifies articles and videos in the same way, and recommends them in the same way. The following recommendation methods are introduced using article recommendation as an example.
S13.获取的用户待评定内容包含信息脱敏后隐藏用户身份关联的性别、年龄等基础信息,以及用户浏览行为信息,包含浏览信息类别、浏览时间和频次等。S13. The obtained user content to be evaluated includes basic information such as gender and age associated with the user's identity after information desensitization, and user browsing behavior information, including browsing information category, browsing time and frequency, etc.
S14.根据S13中产生的各维度信息,产生不同的分类。其中连续型数据根据数值范围确定评分,包含年龄、信息浏览时间、信息浏览频次;离散型数据则根据不同值设定不同分类,包含性别、信息浏览类别。如表1所示,用户评定数据通过表格对应相关分类。S14. Generate different classifications according to the dimension information generated in S13. Among them, the continuous data determines the score according to the numerical range, including age, information browsing time, and information browsing frequency; the discrete data sets different classifications according to different values, including gender and information browsing category. As shown in Table 1, the user evaluation data corresponds to the relevant categories through the table.
表1数据分类规则Table 1 Data classification rules
S15.用户类别分为:普通人群、稳健型人群和进取型人群,人群划分根据用户活跃程度,即每月登录次数及信息浏览次数。普通人群无活跃要求;稳健型人群:每月登录次数大于5,或浏览信息次数大于5;进取型人群:每月登录次数大于10,或浏览信息次数大于10。重点观察进取型人群,此类人群较为主动获取艾滋病相关知识,防范意识较强。新用户初始时各类信息浏览情况为0,在次月根据各类数据情况更新用户类型。S15. User categories are divided into: ordinary people, stable people, and aggressive people. The groups are divided according to the user's activity level, that is, the number of monthly logins and information browsing times. There is no active requirement for the general population; steady population: the number of logins per month is greater than 5, or the number of information browsed is greater than 5; aggressive population: the number of logins per month is greater than 10, or the number of information browsed is greater than 10. Focus on the observation of aggressive people, who are more active in acquiring AIDS-related knowledge and have a strong awareness of prevention. The browsing status of all kinds of information for new users is 0 at the beginning, and the user type is updated according to the status of various data in the next month.
S16.通过智能手机应用收集用户历史浏览信息,该信息随着用户浏览信息的增加而不断增加,作为个性化推荐的依据。S16. Collect user historical browsing information through smart phone applications, and the information will increase continuously with the increase of user browsing information, and serve as the basis for personalized recommendations.
S21.在系统初始,未采集用户浏览信息时,推荐最新信息;在信息浏览量大于第一阈值,本实施例中第一阈值取值为10,向新用户推荐信息浏览量最高的n条信息,若信息浏览量大于10的信息数量小于n,则剩余信息推荐最新信息,进行前期数据累积。n可以根据实际应用需要进行设定,比如n设定为3。S21. At the initial stage of the system, when no user browsing information is collected, recommend the latest information; when the amount of information viewed is greater than the first threshold, in this embodiment, the first threshold is set to 10, and the n pieces of information with the highest amount of information viewed are recommended to new users , if the number of information with more than 10 views is less than n, the remaining information recommends the latest information and accumulates previous data. n can be set according to actual application needs, for example, n is set to 3.
S22.基于用户历史浏览信息,推荐用户感兴趣信息。S22. Based on the historical browsing information of the user, recommend information of interest to the user.
S221.信息相似度计算S221. Information similarity calculation
为解决协同推荐算法面临的数据稀疏性问题,本发明使用KL散度来评估两个信息之间的距离(相似性),无论是否存在相同评定信息此方法都充分利用所有用户评定信息。为了强调不同评级数字在信息之间的影响,信息i和j之间的KL距离计算如下:In order to solve the data sparsity problem faced by the collaborative recommendation algorithm, the present invention uses KL divergence to evaluate the distance (similarity) between two pieces of information, regardless of whether there is the same rating information, this method makes full use of all user rating information. To emphasize the influence of different rating numbers between messages, the KL distance between messages i and j is calculated as follows:

其中,m是相同类别的信息数量,


S222.基于K-medoids的信息聚类S222. Information clustering based on K-medoids
使用KL距离公式(1)从信息概率分布角度找出所有可用信息的k个聚类中心,并生成信息聚类结果。Use the KL distance formula (1) to find out the k cluster centers of all available information from the perspective of information probability distribution, and generate information clustering results.
(1)基于KL距离的k簇中心选择算法(1) K-cluster center selection algorithm based on KL distance
假设数据集R包括N个信息,找出k个聚类中心C={C1,C2,…,Ck},其中Ct代表着第t个聚类中心,初始时C为空。所述k簇中心选择算法如下:Assuming that the data set R includes N pieces of information, find out k cluster centers C={C 1 ,C 2 ,...,C k }, where C t represents the tth cluster center, and C is empty initially. The k-cluster center selection algorithm is as follows:
步骤1.获取第一个聚类中心C1:(i)在i∈N中随机选择信息i作为临时聚类中心C1,j∈N\(i)表示N个信息中除i之外的信息j,计算信息j∈N\(i)和信息i之间的KL距离以获得信息i的KL距离总和∑j∈N\(i)D′(j∥i)。(ii)同样,评估各个信息的KL距离总和。(iii)所有信息中KL距离总和最小的信息作为第一个聚类中心C1,并更新C={C1}。表示如下:Step 1. Obtain the first clustering center C 1 : (i) Randomly select the information i in i∈N as the temporary clustering center C 1 , j∈N\(i) means that among the N pieces of information except i For information j, calculate the KL distance between information j∈N\(i) and information i to obtain the sum of the KL distances of information i ∑ j∈N\(i) D′(j∥i). (ii) Likewise, the sum of the KL distances of the individual messages is evaluated. (iii) The information with the smallest sum of KL distances among all the information is used as the first cluster center C 1 , and C={C 1 } is updated. Expressed as follows:

步骤2:通过迭代选择找出剩余的k-1个聚类中心。Step 2: Find the remaining k-1 cluster centers through iterative selection.
首先选择一个非聚类中心信息i∈N\{C}作为新的临时聚类中心Ci,然后计算信息j∈N\{i,C}和信息i之间的KL距离。利用公式(3)得出所有其他非中心项与临时聚类中心Ci之间的贡献之和DEC(i),通过DEC(i)确定当前迭代的聚类中心。定义DEC(i):对于聚类中心i,先计算其他所有非聚类中心信息j与聚类中心i以及所有其他聚类中心的KL距离的差值的非负最小值,然后将所有信息j计算得到的值求和,计算公式如下:First select a non-cluster center information i∈N\{C} as a new temporary cluster center Ci, and then calculate the KL distance between information j∈N\{i,C} and information i. Use formula (3) to obtain the sum DEC(i) of the contributions between all other non-central items and the temporary clustering center C i , and determine the clustering center of the current iteration through DEC(i). Define DEC(i): For clustering center i, first calculate the non-negative minimum value of the difference between all other non-clustering center information j and the KL distance of clustering center i and all other clustering centers, and then combine all information j The calculated values are summed, and the calculation formula is as follows:

Ct表示当前C中的一个聚类中心,t∈[1,i-1]。以相同的方式,获得所有非聚类中心信息的DEC值。排除已选择的聚类中心点,选择剩余信息中DEC值最大的信息作为新的聚类中心,计算公式如下:C t represents a cluster center in the current C, t∈[1,i-1]. In the same way, obtain the DEC values of all non-cluster center information. Exclude the selected cluster center points, and select the information with the largest DEC value in the remaining information as the new cluster center. The calculation formula is as follows:

新选择的聚类中心Ci加入到C={C1,C2,…,Ci}。The newly selected cluster center C i is added to C={C 1 ,C 2 ,...,C i }.
通过步骤1的操作和步骤2的迭代选择,最终得到k个聚类中心。Through the operation of step 1 and the iterative selection of step 2, k cluster centers are finally obtained.
(2)信息聚类(2) Information clustering
在确定了k个聚类中心之后,计算所有非中心信息j与C中各中心之间的KL距离。根据非中心点与聚类中心之间具有最小KL距离的规则,将其余非中心项信息j∈N\{C}分配到C中与它有最小KL距离的聚类中心Ct中,即

S223.基于Top-n的信息推荐S223. Information recommendation based on Top-n
(1)选择最近邻集(1) Select the nearest neighbor set
通过聚类中心,将类似程度高的信息聚集在一个类中。从该类中挑选信息i的最近邻集。具体选择规则如下:Through the cluster center, information with a high degree of similarity is gathered in one class. Pick the nearest neighbor set of information i from this class. The specific selection rules are as follows:
假设包含信息i的聚类是Ci,通过公式(1)计算KL距离得到聚类Ci中其他信息与信息i之间的KL距离。然后根据KL距离,选择最短距离的n个信息作为为信息i设置的最近邻集,表示为Cneii。Assuming that the cluster containing information i is C i , the KL distance is calculated by formula (1) to obtain the KL distance between other information in cluster C i and information i. Then according to the KL distance, select the n pieces of information with the shortest distance as the nearest neighbor set for information i, denoted as Cnei i .
(2)在线top-n推荐(2) Online top-n recommendation
为了产生用户u的预测信息推荐列表,对所有未评级信息i通过其最近邻居集合Cneii预测信息i在用户u中的评级值pui,计算信息i与该用户u的匹配程度。预测公式介绍如下:In order to generate the predicted information recommendation list for user u, all unrated information i predicts the rating value p ui of information i in user u through its nearest neighbor set Cnei i , and calculates the matching degree between information i and user u. The forecast formula is introduced as follows:


其中,



根据活动用户u对未评级信息的预测评级,选择具有最高预测值的n个信息作为推荐列表。最后,为用户生成在线前n个推荐信息,比如n取值为10。According to the predicted ratings of the unrated information by the active user u, the n pieces of information with the highest predicted value are selected as the recommendation list. Finally, generate the top n online recommendation information for the user, for example, the value of n is 10.
S31.对特定人群推荐更多内容。S31. Recommending more content to specific groups of people.
对于特定人群(进取型人群),判断其感兴趣程度,增加推送相关主题信息(艾滋防治、艾滋治疗)。即在个性化推荐的基础上,补充推荐信息更多的内容,将相关主题信息(艾滋防治、艾滋治疗)中定期内浏览频次最高的前n个信息,额外推送给特定人群(进取型人群)。For specific groups of people (aggressive groups), judge their degree of interest, and increase the push of relevant topic information (AIDS prevention and treatment, AIDS treatment). That is to say, on the basis of personalized recommendation, more recommended information is supplemented, and the top n information with the highest browsing frequency in the relevant topic information (AIDS prevention and treatment, AIDS treatment) is pushed to specific groups of people (aggressive group) .
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。Those skilled in the art will appreciate that the embodiments described here are to help readers understand the principles of the present invention, and it should be understood that the protection scope of the present invention is not limited to such specific statements and embodiments. Various modifications and variations of the present invention will occur to those skilled in the art. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the present invention shall be included within the scope of the claims of the present invention.
Claims (6)
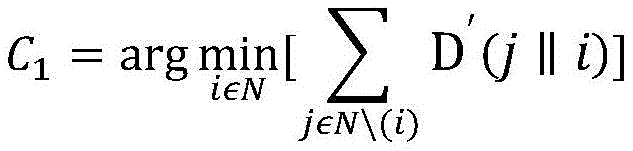





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010336906.6A CN111538913B (en) | 2020-04-26 | 2020-04-26 | A personalized recommendation method for AIDS prevention and control knowledge education |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010336906.6A CN111538913B (en) | 2020-04-26 | 2020-04-26 | A personalized recommendation method for AIDS prevention and control knowledge education |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111538913A CN111538913A (en) | 2020-08-14 |
| CN111538913B true CN111538913B (en) | 2023-07-11 |
Family
ID=71975562
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010336906.6A Expired - Fee Related CN111538913B (en) | 2020-04-26 | 2020-04-26 | A personalized recommendation method for AIDS prevention and control knowledge education |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111538913B (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105956089A (en) * | 2016-05-03 | 2016-09-21 | 桂林电子科技大学 | Recommendation method capable of aiming at classification information with items |
| CN110110181A (en) * | 2019-05-09 | 2019-08-09 | 湖南大学 | A kind of garment coordination recommended method based on user styles and scene preference |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106951418A (en) * | 2016-01-07 | 2017-07-14 | 广州启法信息科技有限公司 | A kind of personalized recommendation technology of business web site |
| CN108205682B (en) * | 2016-12-19 | 2021-10-08 | 同济大学 | A Collaborative Filtering Method Fusion Content and Behavior for Personalized Recommendation |
| CN108334592B (en) * | 2018-01-30 | 2021-11-02 | 南京邮电大学 | A personalized recommendation method based on the combination of content and collaborative filtering |
| US11177025B2 (en) * | 2018-06-20 | 2021-11-16 | International Business Machines Corporation | Intelligent recommendation of useful medical actions |
| CN109192065A (en) * | 2018-08-03 | 2019-01-11 | 电子科技大学 | AIDS video propaganda and education's method and platform based on subject classification |
-
2020
- 2020-04-26 CN CN202010336906.6A patent/CN111538913B/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105956089A (en) * | 2016-05-03 | 2016-09-21 | 桂林电子科技大学 | Recommendation method capable of aiming at classification information with items |
| CN110110181A (en) * | 2019-05-09 | 2019-08-09 | 湖南大学 | A kind of garment coordination recommended method based on user styles and scene preference |
Non-Patent Citations (2)
| Title |
|---|
| 基于主题模型和词向量的短文本语义挖掘研究;李思宇;《中国优秀硕士论文全文数据库(电子期刊)》;全文 * |
| 基于用户行为关系挖掘的个性化推荐模型及算法;郭慧丰;《中国博士学位论文全文数据库(电子期刊)》;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111538913A (en) | 2020-08-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Wang et al. | A sentiment‐enhanced hybrid recommender system for movie recommendation: a big data analytics framework | |
| US9727927B2 (en) | Prediction of user response to invitations in a social networking system based on keywords in the user's profile | |
| CN105740430B (en) | A Personalized Recommendation Method Integrating Social Information | |
| US9122989B1 (en) | Analyzing website content or attributes and predicting popularity | |
| CN105138653B (en) | It is a kind of that method and its recommendation apparatus are recommended based on typical degree and the topic of difficulty | |
| CN108897784B (en) | A Multidimensional Analysis System of Emergencies Based on Social Media | |
| Selke et al. | Pushing the boundaries of crowd-enabled databases with query-driven schema expansion | |
| US20120066073A1 (en) | User interest analysis systems and methods | |
| CN107526850A (en) | Social networks friend recommendation method based on multiple personality feature mixed architecture | |
| CN110110225B (en) | Online education recommendation model and construction method based on user behavior data analysis | |
| CN108804701A (en) | Personage's portrait model building method based on social networks big data | |
| JP2013517563A (en) | User communication analysis system and method | |
| CN107423335B (en) | Negative sample selection method for single-class collaborative filtering problem | |
| CN105608192A (en) | Short text recommendation method for user-based biterm topic model | |
| CN105183833A (en) | User model based microblogging text recommendation method and recommendation apparatus thereof | |
| CN110197404A (en) | The personalized long-tail Method of Commodity Recommendation and system of popularity deviation can be reduced | |
| US20160110730A1 (en) | System, method and computer-accessible medium for predicting user demographics of online items | |
| Wang et al. | Memetic algorithm based location and topic aware recommender system | |
| Chaturvedi et al. | Recommender system for news articles using supervised learning | |
| Bogaert et al. | Predicting Self‐declared movie watching behavior using Facebook data and Information‐Fusion sensitivity analysis | |
| CN104572915A (en) | User event relevance calculation method based on content environment enhancement | |
| US20190130360A1 (en) | Model-based recommendation of career services | |
| CN117171449B (en) | Recommendation method based on graph neural network | |
| CN111538913B (en) | A personalized recommendation method for AIDS prevention and control knowledge education | |
| Singh et al. | Investigating the heterogeneity of product feature preferences mined using online product data streams |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20230711 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |