CN113519001A - Generating common sense interpretations using language models - Google Patents
Generating common sense interpretations using language models Download PDFInfo
- Publication number
- CN113519001A CN113519001A CN202080018455.XA CN202080018455A CN113519001A CN 113519001 A CN113519001 A CN 113519001A CN 202080018455 A CN202080018455 A CN 202080018455A CN 113519001 A CN113519001 A CN 113519001A
- Authority
- CN
- China
- Prior art keywords
- question
- text
- interpretation
- module
- answer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 claims abstract description 61
- 238000013528 artificial neural network Methods 0.000 claims abstract description 18
- 238000012549 training Methods 0.000 claims description 31
- 230000004044 response Effects 0.000 claims description 4
- 238000013136 deep learning model Methods 0.000 abstract description 16
- 238000013473 artificial intelligence Methods 0.000 abstract description 15
- 238000009966 trimming Methods 0.000 abstract 1
- 238000013145 classification model Methods 0.000 description 32
- 230000008569 process Effects 0.000 description 17
- 238000010586 diagram Methods 0.000 description 13
- 230000015654 memory Effects 0.000 description 9
- 241000282412 Homo Species 0.000 description 8
- 238000003058 natural language processing Methods 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 3
- 235000015220 hamburgers Nutrition 0.000 description 3
- 238000003062 neural network model Methods 0.000 description 3
- 230000011218 segmentation Effects 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 230000002457 bidirectional effect Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000010801 machine learning Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000006403 short-term memory Effects 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 241000726124 Amazona Species 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- 230000001143 conditioned effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000000153 supplemental effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Mathematical Physics (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Abstract
According to some embodiments, systems and methods are provided for developing or providing common sense automated generation interpretation (CAGE) for prediction by inference used by artificial intelligence, neural networks, or deep learning models. In some embodiments, the systems and methods generate such interpretations using supervised trimming of Language Models (LMs). These interpretations can then be used for downstream classification.
Description
The inventor: n, Lajiani and B, Mackaen
RELATED APPLICATIONS
This application claims priority from U.S. provisional patent application No. 62/813,697 filed on 3/4/2019 and U.S. non-provisional patent application No. 16/393,801 filed on 24/4/2019, the entire contents of which are incorporated herein by reference.
Copyright notice
A portion of the disclosure of this patent document contains material which is subject to copyright protection. The copyright owner has no objection to the facsimile reproduction by anyone of the patent document or the patent disclosure, as it appears in the patent and trademark office patent file or records, but otherwise reserves all copyright rights whatsoever.
Technical Field
The disclosure relates generally to natural language processing, and more particularly to generating a common sense interpretation (common interpretation) of reasoning (reasoning) or rationalization (ratification) using (leveraging) language models.
Background
Artificial intelligence implemented using neural networks and deep learning models has emerged as a great prospect as a technique for automatically analyzing real-world information with human-like (human-like) accuracy. However, artificial intelligence or deep learning models are generally unable to explain the reasoning behind their predictions or rationalization of the predictions, or to explain how well the reasoning or rationalization is based on common sense knowledge. This makes it difficult for humans to understand and trust such models.
Accordingly, it would be advantageous to have a system and method that provides, implements, or improves on common sense reasoning or rationalization in artificial intelligence or deep learning models, and additionally generates or provides an explanation of the reasoning or rationalization.
Drawings
Fig. 1 is a simplified diagram of a computing device, according to some embodiments.
Fig. 2 illustrates an example of questions, answers, and human generated interpretations that may be included in a common sense interpretation (CoS-E) dataset, according to some embodiments.
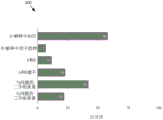
Fig. 3 illustrates an example distribution of interpretations collected in a CoS-E dataset, according to some embodiments.
FIG. 4 illustrates example time steps for training a common sense Auto-Generated extensions (CAGE) language model to generate an interpretation from a CoS-E dataset, according to some embodiments.
Fig. 5 is a simplified diagram of a language module or model according to some embodiments.
Fig. 6 illustrates example time steps for generating a predictive classification model or module according to some embodiments.
Fig. 7 is a simplified diagram of a classification model or module according to some embodiments.
Fig. 8 is a simplified diagram illustrating a system for generating a common sense interpretation of inferences through artificial intelligence or deep learning models, according to some embodiments.
Fig. 9 is a simplified diagram of a method of generating a common sense interpretation of inference through artificial intelligence or deep learning models, according to some embodiments.
Fig. 10 is a simplified diagram illustrating a system for generating a rationalized common sense interpretation through artificial intelligence or deep learning models, according to some embodiments.
Fig. 11 is a simplified diagram of a method of generating a rationalized common sense interpretation through artificial intelligence or deep learning models, according to some embodiments.
FIG. 12 illustrates a table showing an example set of inferences and rationalizations from common sense QA (CommonseQA), CoS-E, and CAGE samples according to some embodiments.
Fig. 13 shows a table showing the result comparison.
In the drawings, elements having the same reference number have the same or similar function.
Detailed Description
The description and drawings illustrating various aspects, embodiments, implementations or applications should not be taken as limiting-the claims define the claimed invention. Various mechanical, compositional, structural, electrical, and operational changes may be made without departing from the spirit and scope of the description and claims. In some instances, well-known circuits, structures or techniques have not been shown or described in detail as they would be known to one skilled in the art. The same numbers in two or more drawings identify the same or similar elements.
In the description, specific details are set forth describing some embodiments according to the disclosure. Numerous specific details are set forth in order to provide a thorough understanding of the embodiments. It will be apparent, however, to one skilled in the art, that some embodiments may be practiced without some or all of these specific details. The specific embodiments disclosed herein are intended to be illustrative rather than restrictive. Those skilled in the art will recognize that, although not specifically described herein, other elements are within the scope and spirit of the disclosure. Furthermore, to avoid unnecessary repetition, one or more features shown and described in connection with one embodiment may be incorporated into other embodiments unless specifically described otherwise or the one or more features would render the embodiments inoperative.
SUMMARY
Artificial intelligence implemented using neural networks and deep learning models has emerged as a great prospect as a technique for automatically analyzing real-world information with human-like accuracy. Typically, such neural networks and deep learning models receive input information and make predictions based on the input information. However, these models may face the challenge of applying common sense reasoning or rationalization to develop or interpret their predictions. Common sense reasoning or rationalization is a challenging task of modern machine learning methods. Artificial intelligence or deep learning models often fail to explain the reasoning or rationalization (common sense or otherwise) behind their predictions, making it difficult for humans to understand and trust such models.
Applying common sense reasoning or rationalizing and interpreting will help make the deep neural network more transparent to humans and establish trust.
According to some embodiments, the disclosure provides systems and methods for generating interpretations useful for common sense reasoning or rationalization using a pre-trained language model. In some embodiments, a common sense automated generation interpretation (CAGE) is provided as a framework for interpretation of the generation of common sense question and answer (common sense QA). Common sense QA is a multi-choice Question-and-answer dataset proposed for developing Natural Language Processing (NLP) models with common sense reasoning capabilities, as described in detail in Talmor et al, "A Question Answering Change Targeting Commensense Knowledge Knowledge," arXiv:1811.00937v2 (11/2/2018), which is incorporated herein by reference. There are multiple versions of common sense QA (e.g., v1.0, v1.1), any of which may be used in one or more embodiments. NLP is a class of problems that neural networks may be suitable for. NLP can be used to instill (instill) an understanding of individual words and phrases into a new neural network.
In some embodiments, a human interpretation of the common sense inference is generated and established outside or added to the corpus of common sense QA (corpus) as a common sense interpretation (CoS-E). In some embodiments, CoS-E contains human interpretations in the form of both open-ended natural language interpretations and highlighted span annotations (highlighted span annotation) that represent words selected by humans as important for predicting correct answers.
According to some embodiments, the task of common sense reasoning is broken down into two phases. In the first stage, the system and method of disclosure provides a common sense QA example and a corresponding CoS-E interpretation for the language model. The language model determines the question and answer choices from the examples and is trained to generate the CoS-E interpretations. In the second phase, the system and method of disclosure uses the language model to generate an interpretation for each example in the training and verification set of the common sense QA. These common sense automatic generation interpretations (CAGE) are provided to the second common sense inference model by concatenating (concatement) the second common sense inference model to the end of the output of the original question, answer selection and language model. The two-stage CAGE framework achieves state-of-the-art results that exceed the best reported baseline by 10%, and also produces an explanation to prove that its prediction is a common sense auto-generated explanation (CAGE).
In summary, the disclosure presents a new common sense interpretation (CoS-E) dataset to study neural common sense reasoning. The disclosure provides a new method (CAGE) for automatically generating an interpretation based on common sense QA, which achieves an accuracy of about 65% of the prior art.
Computing device
Fig. 1 is a simplified diagram of a computing device, according to some embodiments. As shown in fig. 1, computing device 100 includes a processor 110 coupled to a memory 120. The operation of computing device 100 is controlled by processor 110. Also, while computing device 100 is shown with only one processor 110, it is understood that processor 110 may represent one or more central processing units, multi-core processors, microprocessors, microcontrollers, digital signal processors, Field Programmable Gate Arrays (FPGAs), Application Specific Integrated Circuits (ASICs), Graphics Processing Units (GPUs), etc. in computing device 100. Computing device 100 may be implemented as a stand-alone subsystem, a panel (board) added to a computing device, and/or a virtual machine.
Memory 120 may be used to store software executed by computing device 100 and/or one or more data structures used during operation of computing device 100. Memory 120 may include one or more types of machine-readable media. Some common forms of machine-readable media may include a floppy disk, a flexible disk, hard disk, magnetic tape, any other magnetic medium, a CD-ROM, any other optical medium, punch cards, paper tape, any other physical medium with patterns of holes, a RAM, a PROM, an EPROM, a FLASH-EPROM, any other memory chip or cartridge, and/or any other medium from which a processor or computer can read.
The processor 110 and/or the memory 120 may be arranged in any suitable physical arrangement. In some embodiments, processor 110 and/or memory 120 may be implemented on the same panel, in the same package (e.g., a system-in-package), on the same chip (e.g., a system-in-chip), and so on. In some embodiments, processor 110 and/or memory 120 may include distributed, virtualized, and/or containerized computing resources. Consistent with such embodiments, processor 110 and/or memory 120 may be located in one or more data centers and/or cloud computing facilities.
As shown, the memory 120 includes a common sense interpretation module 130 that can be used to implement and/or simulate systems and models, and/or implement any of the methods described further herein. In some examples, the common sense interpretation module 130 can be used to develop, derive, or generate predictions, apply common sense reasoning or rationalization, and generate or provide the same interpretation as further described herein. In some examples, the common sense interpretation module 130 can also handle iterative training and/or evaluation of systems or models used to generate predictions, apply common sense reasoning or rationalize, and generate or provide an interpretation. In some examples, memory 120 may include a non-transitory, tangible machine-readable medium comprising executable code that, when executed by one or more processors (e.g., processor 110), may cause the one or more processors to perform a method described in further detail herein. In some examples, the common sense interpretation module 130 may be implemented using hardware, software, and/or a combination of hardware and software.
As shown, the computing device 100 receives input data 140 and natural language interpreted text 145 that are provided to the common sense interpretation module 130. The input data 140 may relate to any situation, scenario, question, etc. that it is desirable to apply artificial intelligence, neural networks, or deep learning models to analyze and make predictions, e.g., for question-answering (QA) or some other NLP task. In some embodiments, the natural language interpretation text 145 may include a human interpretation of a common sense inference, which may be a common sense interpretation (CoS-E). The human interpretation may be in the form of an open natural language interpretation as well as a highlighted annotation in the original input instance. In some embodiments, the natural language interpretation text 145 may include automatically generated interpretations. The natural language interpreted text 145 may be used for fine tuning or training of the common sense interpretation module 130. In some embodiments, this training may occur over one or more iterations performed or conducted by the common sense interpretation module 130.
The common sense interpretation module 130 operates on the input data 140 to develop, derive or generate predictions or results, which are performed using natural language interpretation text 145 to support or apply common sense reasoning. The module 130 may also generate or provide an explanation of its reasoning or rationalization. In some embodiments, the common sense interpretation module 130 implements or incorporates a Language Model (LM) that can generate an interpretation. In some embodiments, the common sense interpretation module 130 implements or incorporates a common sense inference model (CSRM) or classification model that develops or generates predictions or results based at least in part on interpretations from a Language Model (LM). In some embodiments, the common sense interpretation module 130 uses or incorporates a Generative Pre-Trained Transformer (GPT) language model (e.g., Radford et al, "stimulating language understanding by Generative Pre-training," or "stimulating language understanding," or "genetic training Pre-training," or "genetic training," or "genetic training, or"https://s3-us-west-2.amazonaws.com/ openai-assets/research-overs/language-unsupervised/language understanding a paper.pdfFurther described, incorporated herein by reference) and fine-tuned over the common sense QA training data through determination of questions, answer choices, and human-generated interpretations. The results and interpretation are provided as output 150 from the computing device 100.
In some examples, the common sense interpretation module 130 may include a single or multi-layer neural network with appropriate preprocessing, encoding, decoding, and output layers. Neural networks have shown great promise as a technique to automatically analyze real-world information with human-like accuracy. Typically, neural network models receive input information and make predictions based on the input information. While other methods of analyzing real world information may involve hard-coding processes, statistical analysis, etc., neural networks learn to predict step-by-step through trial-and-error processes using machine learning processes. A given neural network model may be trained using a large number of training examples, iteratively until the neural network model begins to consistently make similar inferences from the training examples that a human may make. Although the common sense interpretation module 130 is depicted as a software module, it may be implemented using hardware, software, and/or a combination of hardware and software.
Common sense interpretation (CoS-E)
According to some embodiments, the language modeling system and method of disclosure may use or utilize human interpretation of common sense reasoning, which may be in a common sense interpretation (CoS-E) dataset. In some embodiments, the CoS-E dataset is added to or constructed on top of an existing common sense QA dataset for use in the language model system and method of disclosure. The common sense QA dataset consists of two segmentations (splits), as described by Talmor et al, "A Question Answering Change Targeting Commensense Knowledge Knowledge," arXiv:1811.00937v2 (11/2/2018), which is incorporated herein by reference. In some embodiments, the CoS-E dataset and language model of the disclosure uses a more difficult stochastic segmentation, i.e., a primary assessment segmentation. Each example in the common sense QA consists of a question q, three answer choices c0, c1, c2 and a labeled answer a. CoS-E dataset with human interpretation E addedhFor explaining why a is the most appropriate choice.
In some embodiments, human interpretations of the common sense inference for the CoS-E dataset can be collected, for example, using Amazon Mechanical turn (MTurk). As shown in the example shown in fig. 2, the system presents or presents one or more questions 210 (e.g., "what did people try to do when eating hamburgers with friends. The system prompts the human participants for the following questions: "why is the predicted output the most appropriate answer? ". The system instructs the human participant to highlight relevant words 240 in the question 210 that prove the true answer selection 230 is correct (e.g., "hamburger, with friend"), and provides a short open interpretation 250 based on the highlighted proof (e.g., "often eat hamburger with friend to indicate nice time"), which can be used as a common sense inference behind the question. The system collects these interpretations to add to or build on top of the common sense QA training-random-segmentation and de-random-segmentation, which may have sizes of 7610 and 950 examples, respectively. The resulting CoS-E dataset includes both free-form interpretations and highlighted text of questions, answer choices, and true answer choices. The highlighted text or words 240 in the dataset may be referred to as "CoS-E-selected" and the free form interpretation 250 may be referred to as "CoS-E-open".
With respect to human-generated interpretations that gather common sense inferences, it may be difficult to control the quality of open annotations (e.g., interpretations 250) provided by participants interacting with the system. Thus, in some embodiments, the system may perform an in-browser check to avoid or reject a visibly erroneous interpretation. In some embodiments, the human annotator is not allowed to proceed forward in the system if s/he does not highlight the relevant words 240 in the question 210 or if the length of the interpretation 250 is less than four words. The system may also check that the interpretation 250 is not a substring of the question 20 or answer selection 220 without any other additional words. In some embodiments, the system collects these interpretations 250 from one annotator per example. The system may also perform one or more post-collection checks to capture instances that are not captured or identified by other filters. The system may filter out interpretations 250 that may be classified as templates. For example, the form "< answer > is the only option, i.e., [ correctly obvious ]" interpretations can be deleted by the system and then re-rendered by the same or a different human participant for annotation.
Fig. 3 illustrates an example distribution 300 of interpretations (e.g., the open interpretation 250 of fig. 2) collected in a CoS-E dataset in some embodiments. As shown in fig. 3, 58% of the interpretations from the CoS-E dataset contain a true answer selection (e.g., true answer selection 230) — case "a". 7% of the interpretations include interferers (or wrong selection of a problem) — case "B". 12% of the interpretations include true and interferents (A and B), while 23% of the interpretations do not include true or interferents (neither A nor B). 42% of interpretations have a bigram overlap with a question (e.g., question 210), while 22% of interpretations have a trigram overlap with a question.
In some embodiments, a human-generated interpretation of the CoS-E dataset (e.g., the interpretation 250 of fig. 2) may be provided, for example, as natural language interpreted text 145 that is input to the computing device 100 (fig. 1) for use by the common sense and interpretation module 130. According to some embodiments, the CoS-E dataset is added to an existing common sense QA dataset for the language model systems and methods, e.g., as implemented or incorporated in module 130. The usefulness of the Language Model (LM) to use the CoS-E data set is not limited to those specific examples of data sets. In some embodiments, the language model obtains state-of-the-art results by using the CoS-E dataset only during training. Empirical results show that even using only those interpretations that do not have any word overlap with any answer selection, the performance completely exceeded that of the baseline without the CoS-E dataset. It was also observed that there was also a significant proportion of interferent selections in the CoS-E dataset, and in further analysis, we found that for those examples, the annotator explained by eliminating the wrong selections. This indicates that even for humans, it is difficult to deduce many examples of common sense QA. CoS-E also adds a view of diversity to the common sense QA dataset, especially a diversity inference on world knowledge. Even though many interpretations are still noisy after the quality control checks, the interpretations of the CoS-E data set are of sufficient quality to train a language model that produces common sense inferences.
Common sense automatic generation interpretation (CAGE)
Language model systems and methods may develop, derive, or generate predictions or results of NLP tasks (e.g., question-answering). According to some embodiments, the language model systems and methods of disclosure generate or output interpretations of their reasoning and principles (rationales) -common sense automated generation interpretations (CAGEs) for their predictions or results. In some embodiments, for example, a language model or module, as implemented or incorporated in the common sense interpretation module 130, generates these interpretations in response to or using the input data 140 and the natural language interpretation text 145. Interpretations are generated by the language model and used as supplemental input to the classification model or module.
In some embodiments, CAGE is provided and applied to the common sense QA task. As previously described, each example in the common sense QA consists of a question q, three answer choices c0, c1, c2, and a labeled answer a; and the CoS-E dataset adds a human explanation of why a is the most appropriate choice Eh. The output of CAGE is the interpretation e of the language model generation, which is trained to be close to eh。
According to some embodiments, to provide CAGE to the classification model, the Language Model (LM) is trimmed or modified to generate an interpretation from the CoS-E data set. In some embodiments, the Language model of the disclosure may be implemented or combined with a Pre-Trained OpenAI generation Pre-Trained-Transformer (GPT), as further detailed in Radford et al, "Improving Language Understanding by general Training Pre-Training," https:// s3-us-west-2. amazonas. com/OpenAI-apparatuses/research-coverage/Language-intersection paper. pdf,2018, which is incorporated herein by reference. GPT is a multi-layer transformer (see Vaswani et al, 2017, incorporated herein by reference) decoder.
In some embodiments, a Language Model (LM) (e.g., that of GPT) is refined or trained on a combination of common sense QA datasets and CoS-E datasets. This is shown, for example, in fig. 4 and 5. FIG. 4 shows one time step in training the CAGE Language Model (LM) or module 405 to generate interpretations from the CoS-E dataset. In some embodiments, the language model may be implemented in or be part of common sense interpretation module 130 (FIG. 1). As illustrated, the language model 405 is based on answer selection tokens (tokens) A1、A2、A 3420 and a previously human-generated interpreted token E1、...E i-1430 in series with the question token Q410. Training Language Model (LM) or module 405 to generate an interpreted token E i 440。
FIG. 5 is a language module or model 505 according to some embodimentsIs shown in simplified form. In some embodiments, the language model 505 may be consistent with the common sense interpretation module 130 and/or the language model 405. In some examples, language model 505 is a multi-layer neural network. As shown in fig. 5, in some embodiments, the multi-layer neural network may be a multi-layer transducer encoder that includes an embedding module 510 and a transducer module 512. In some embodiments, the embedding module 510 may include an embedding layer (E)1、E2、...EN) And the transformer module 512 may include one or more layers of transformers (Trm). In some embodiments, each converter (Trm) may be implemented using Long Short Term Memory (LSTM). The language model or module 505 receives structured source text x, such as input data 140, in the form of question (Q) and answer choices. In some embodiments, the structured source text x is in natural language form. The structured source text x is passed to the embedding layer (E)1、E2、...EN) Which decomposes the structured source text into tokens xiWherein each token xiMay correspond to words, numbers, labels, etc. In some embodiments, as shown, the language model or module 505 uses constrained self-attention at the transformer (Trm) level, where each token can only notice the context to its left. These left-side-only context transformer (Trm) layers collectively act as a transformer decoder for text generation. Generated text (T)1、T2、...TN) For general knowledge interpretation Ei. In some embodiments, such an interpretation may be used to infer which answer selection is correct for the question.
In view of human interpretation from the CoS-E or inference/interpretation from language models or modules (e.g., 405 or 505), the systems and methods of disclosing content can learn to perform predictions of common sense QA tasks. In some embodiments, such as shown in fig. 6 and 7, the classification model or module generates or derives predictions made for the input question-set. FIG. 6 shows one time step in generating a predictive classification model (CRSM) 615. In some embodiments, the classification model may be implemented in or be part of the common sense interpretation module 130 (FIG. 1). As shown, a classification model or module 615 receives andanswer selection token A1、A2、A 3620, and generates or derives a predicted token a1 650。
In some embodiments, the classification model or module 615 may be implemented or employ a Language representation model, such as a Bidirectional Encoder representation from transducers (BERT) model, as described in Devlin et al, "BERT: Pre-training of Deep Bidirectional transducers for Language interpretation," arXiv prediction arXiv:1810.04805 (11/10/2018), which is incorporated herein by reference. In some embodiments, classification model 615 may be implemented or employ BERTLARGEModels that can be fine-tuned for multiple choice question answering by adding simple binary classifiers. The classifier will correspond to a special [ CLS ] placed at the beginning of all inputs of the BERT model]The final state of the token serves as input. For each example in the dataset, classification model 615 is constructed to fine-tune the BERTLARGEThree input sequences of the model. The input representation of the description is the same as the input representation of the question.
Fig. 7 is a simplified diagram of a classification model or module 715 according to some embodiments. In some embodiments, the classification model 715 may be in accordance with the common sense interpretation module 130 and/or the classification model 615. In some examples, classification model 715 is a multi-layer neural network. As shown in fig. 7, in some embodiments, the multilayer neural network may be a multilayer transformer encoder including an embedding module 710 and a transformer module 712. In some embodiments, the embedding module 710 may include an embedding layer (E)1、E2、...EN) And the transformer module 712 may include one or more layers of transformers (Trm). In some embodiments, a long term short term memory (LSTM) layer may be used instead of a transducer layer. The classification model or module 715 receives the structured source text x in the form of question (Q) and answer choices, such as the input data 140. In some embodiments, the structured text may also include interpretations generated, for example, by a trained language model (e.g., 405 or 505). Question, answer selection and interpretation are separated by partitions in the input dataSymbol [ SEP ]]And (4) separating. In some embodiments, each sequence is a question, delimiter token [ SEP ]]And a concatenation of answer choices. If the method requires an interpretation from CoS-E or generated automatically as in CAGE, the classification model or module 715 will question [ SEP]Explain [ SEP ]]And answer choices are concatenated. The structured source text x is passed to the embedding layer (E)1、E2、...EN) Which decomposes the structured source text into tokens xiWherein each token xiMay correspond to words, numbers, labels, etc. In some embodiments, as shown, the classification model 715 uses two-way self-attention at the transformer (Trm) level, where each token can note context to its left and right. These transformer (Trm) layers collectively function as a transformer encoder. The classification model or module 715 generates or derives a prediction of answer choices for the input question.
Two settings or possibilities for generating the interpretation and prediction may be: (1) interpretation-then-prediction ("inference"); and (2) predict-then-explain ("rationalize").
Reasoning: reasoning is explained with reference to fig. 8 and 9. Fig. 8 is a simplified diagram illustrating a system for generating a common sense interpretation for inference through artificial intelligence or deep learning models, according to some embodiments. Fig. 9 is a simplified diagram of a corresponding method 900 for the system 800. One or more of the processes 910 and 940 of the method 900 may be implemented at least in part in executable code stored on a non-transitory, tangible, machine-readable medium, which when executed by one or more processors, may cause the one or more processors to perform one or more of the processes 910 and 940. In some embodiments, the system 800 may be implemented in the computing device 100 of fig. 1 (e.g., the common sense interpretation module 130), and the method 900 may be performed by the computing device 100 of fig. 1 (e.g., the common sense interpretation module 130).
With inference, as shown in fig. 8 and 9, an interpretation 840 of a downstream taxonomy or common sense inference model (CSRM)815 is generated using a trained CAGE language model 805 (which may be consistent with language models or modules 405 and 505).
For training, at process 910, language model 80And 5, receiving the natural language interpretation text. In some examples, natural language interpreted text (e.g., text 145) may include question q and answer selections c0, c1, c2 collected from or developed by humans, and interpretations eh。
In some embodiments, the task of collecting or developing interpretations from humans consists of two parts. In the first section, the human annotator is instructed to highlight relevant words in the question that the proof output is correct. In the second section, the annotator is required to provide a brief open explanation as to why the predicted output is correct, but not other choices. These instructions cause the annotator to provide interpretations that actually provide a common reasoning behind the problem. In some embodiments, natural language interpreted text is used to train, test, and run language model 805.
By inference, based on question q, answer choices c0, c1, c2 and human-generated interpretation ehRather than the actual predicted tag or answer a to fine tune the Language Model (LM) 805. Thus, the input context C during trainingREThe definition is as follows:
CREis "q, c0, c1 or c 2? General knowledge "
The target training language model 805 is modeled from the conditional language to generate an interpretation e.
After system 800 (e.g., language model 805) is trained, language model 805 and classification model or module 815 receive input data (e.g., input data 140) at process 920. The input data may relate to any situation, scenario, problem, etc. for which it is desirable to apply artificial intelligence, neural networks, or deep learning models for analysis and prediction. In some embodiments, as shown, the input data may include question Q810 and answer selection A1、A2、A 3 820。
At process 930, the language model 805 generates or develops an interpretation E840 of the common sense inference for the potential prediction or outcome of the input data. This may be accomplished, for example, as described with respect to language models 405 and 505 of fig. 4 and 5. The machine-generated common sense interpretation 840 is provided to the classification model 815.
At process 940, classification model or module 815 (which may be consistent with classification models or modules 615 and 715) operates on the input data (e.g., question set 810 and answer selections 820) to develop, derive, or generate predictions or results 850. In some examples, the classification model 815 uses machine-generated interpretations 840 to support or apply common sense reasoning in its analysis. This may be accomplished, for example, as described with respect to classification models 615 and 715 of fig. 6 and 7.
In some embodiments, the goal is to maximize:

where k is the size of the context window (in this case k is always larger than the length of e, so that the whole interpretation is within the context). Conditional probability P by having CREAnd a parameter Θ that previously interpreted the token as a condition. This interpretation may be referred to as "reasoning" because it may be automatically generated during reasoning to provide additional context for the common sense question-answer. It is shown below that this method outperforms the reported state of the art of conventional sense QA by 10%.
The results and interpretation of the common sense inference are provided as an output (e.g., output 150 from common sense interpretation module 130).
Rationalization of: the reverse approach to reasoning is rationalized. Rationalization is shown with respect to fig. 10 and 11. Fig. 10 is a simplified diagram illustrating a system 1000 for generating a common sense interpretation for rationalization through artificial intelligence or deep learning models, according to some embodiments. Fig. 11 is a simplified diagram of a corresponding method 1100 for the system 1000. One or more of the processes 1110 and 1140 of the method 1100 may be implemented at least in part in executable code stored on a non-transitory, tangible, machine-readable medium, which when executed by one or more processors, causes the one or more processors to perform one or more of the processes 1110 and 1140. In some embodiments, system 1000 may be implemented in computing device 100 of fig. 1 (e.g., common sense interpretation module 130), and method 1100 may be performed by computing device 100 of fig. 1 (e.g., common sense interpretation module 130)Common sense interpretation module 130).
By rationalizing, as shown in fig. 10 and 11, a classification model or module 1015 (which may be consistent with classification models or modules 615 and 715) first makes predictions a, and then a language model or module 1005 (which may be consistent with language models or modules 405 and 505) generates interpretations based on those tags.
For training, at process 1110, classification model 1015 operates on input data (e.g., question set 1010 and answer selection 1020) to develop, derive, or generate predictions or results 1050. A language model or module 1005 receives natural language interpreted text. In some examples, the natural language interpretation text (e.g., text 145) may include question q and answer selections c0, c1, c2, and an interpretation e collected from or developed by a person as previously describedh。
In process 1120, language model 1005 and classification model 1015 receive input data (e.g., input data 140). The input data may relate to any situation, scenario, problem, etc. for which it is desirable to apply artificial intelligence, neural networks, or deep learning models for analysis and prediction. In some embodiments, as shown, the input data may include question Q1010 and answer selection A1、A2、A 3 1020。
At process 1130, the classification model or module 1015 operates on the input data to develop, derive, or generate predictions or results 1050. This may be accomplished, for example, consistent with the description of the classification models or modules 615 and 715 of fig. 6 and 7. The results 1050 are provided to the language model 1015.
In rationalization, at process 1140, the conditions on the prediction label a of language model 1015 are used with the input to generate causal rationalization, or in other words, to generate an interpretation of the reasoning used to make the prediction. During the fine-tuning step of the language model 1015, context C is inputRAContains an output tag a and is constructed as follows:
CRAq, c0, c1 or c2a because "
The training goals of the language model 1015 in rationalization are similar to those in reasoning, except that in this case the model 1015 can obtain a true label of the input question during training.
Because the language model or module 1015 conditions the predictive tags, the interpretation is not considered a common sense inference. Instead, they provide "rationalization" that makes the model more accessible and interpretable. It has been found that this rationalization approach is 6% better than the prior art model, as described below.
With respect to the systems and methods of fig. 8-11, some examples of a computing device, such as computing device 100, may include a non-transitory, tangible, machine-readable medium that includes executable code, which when executed by one or more processors (e.g., processor 110), may cause the one or more processors to perform the processes of methods 900 and 1100. Some common forms of machine-readable media that may include the processes of methods 900 and 1100 are, for example, a floppy disk, a flexible disk, hard disk, magnetic tape, any other magnetic medium, a CD-ROM, any other optical medium, punch cards, paper tape, any other physical medium with patterns of holes, a RAM, a PROM, an EPROM, a FLASH-EPROM, any other memory chip or cartridge, and/or any other medium from which a processor or computer is adapted to read.
Results
Results on a common sense QA dataset using the proposed variants of common sense automated generation interpretation (CAGE) are presented. BERTLARGEThe model was used as a baseline without any CoS-E or CAGE.
FIG. 12 shows a table 1200 showing an example set of samples from common sense QA, CoS-E, and CAGE (for reasons and rationale). It can be observed that, in some embodiments, CAGE-inference generally takes a simpler construction than CoS-E-open. Nevertheless, this simple declarative schema can sometimes be more informative than CoS-E-opening. The system and method of implementing the CAGE disclosure accomplishes this by providing more explicit guidance (as in the last example 1202 of table 1200) or by adding meaningful context (as in the third example 1204 by introducing the word 'friend'). It is observed from table 1200 that, in some embodiments, CAGE-inference contains at least one of the answer choices 43% of the time, among which it contains the actual predicted answer choice for the model 21% of the time. This indicates that CAGE-reasoning is more efficient than direct-directed answers.
As can be seen from table 1200, CAGE-rationalization and CAGE-reasoning are generally the same, or differ only in word order, or by replacing one answer choice with another. Based only on the age of CAGE-rationalized 42% of the time, humans can predict responses, as with CAGE-reasoning. Although CAGE-rationalization appears to be better than CAGE reasoning, we have found that it does not significantly improve the language-generated behavior of the model, i.e., the behavior of human judgment, when trying to guess the correct answer without actual questions.
Additional experimental setups use only open explanations that do not contain any words from any answer selection. These interpretations may be referred to as "CoS-E-Limited open" interpretations because they are limited in terms of allowed word choice. We observed that even using these limited interpretations improved the BERT baseline, suggesting that these interpretations provide useful information, not just to mention correct or incorrect answers.
Fig. 13 shows a table 1300 showing results achieved using BERT baseline using only common sense QA inputs compared to systems and methods trained using inputs containing descriptions from CoS-E according to embodiments of the disclosure. As seen in table 1300, the BERT baseline model achieved 64% accuracy. Adding an open human interpretation (CoS-E-open) next to the question during training results in a 2% improvement in the accuracy of the question-answering model. The accuracy of the model increased to 72% when the model was further provided with interpretations generated by CAGE-inference (not conditioned on reality) during training and validation.
This description and drawings, illustrating inventive aspects, embodiments, implementations or applications, should not be taken in a limiting sense. Various mechanical, compositional, structural, electrical, and operational changes may be made without departing from the spirit and scope of the description and claims. In some instances, well-known circuits, structures or techniques have not been shown or described in detail to avoid obscuring implementations of the invention. The same numbers in two or more drawings identify the same or similar elements.
In the present specification, specific details are set forth describing some embodiments according to the disclosure. Numerous specific details are set forth in order to provide a thorough understanding of the embodiments. It will be apparent, however, to one skilled in the art, that some embodiments may be practiced without some or all of these specific details. The specific embodiments disclosed herein are intended to be illustrative rather than restrictive. Those skilled in the art will recognize other elements that, although not specifically described herein, are within the scope and spirit of the disclosure. Furthermore, to avoid unnecessary repetition, one or more features shown and described in connection with one embodiment may be incorporated into other embodiments unless specifically described otherwise or if one or more features would render the embodiments inoperative.
While exemplary embodiments have been shown and described, a wide range of modifications, changes, and substitutions is contemplated in the foregoing disclosure and in some instances, some features of the embodiments may be employed without a corresponding use of the other features. One of ordinary skill in the art would recognize many variations, alternatives, and modifications. Accordingly, the scope of the invention should be limited only by the attached claims, and, as appropriate, the claims should be construed broadly and in a manner consistent with the scope of the embodiments disclosed herein.
Claims (20)
1. A method, comprising:
encoding and embedding, by an embedding module, structured source text for a question and answer set, the question and answer set comprising a question and a plurality of answer choices;
iteratively decoding, by a multi-layer transformer module, an output of the embedding module based on the generated tokens related to the structured interpretation text from the previous iteration to generate an interpretation text for inferring which answer selection is correct for the question, wherein the structured interpretation text from the previous iteration comprises interpretation text generated by a human annotator;
providing the generated interpretation text to a classification module; and
using the generated interpretation text, a prediction is generated at the classification module which answer selection is correct for the question.
2. The method of claim 1, wherein the structured source text of the question-and-answer set comprises text in natural language form.
3. The method of claim 1 or 2, comprising collecting the structured interpretation text from the human annotator.
4. The method of claim 3, wherein collecting the structured interpretation text comprises:
providing the human annotator with a set of training questions and answers; and
receiving the structured interpretation text from the human annotator in response to the training set of questions and answers.
5. The method of any of claims 1-4, comprising providing the set of questions and answers to the classification module, wherein the questions, the plurality of answer choices, and the generated interpretation text are separated by delimiters when provided to the classification module.
6. The method of any of claims 1-5, wherein the embedding module and the multilayer transformer module comprise at least a portion of a natural language model.
7. The method of any of claims 1-6, wherein the classification module comprises a multilayer transformer encoder.
8. A system, comprising:
an embedding module to encode and embed structured source text for a question-and-answer set, the question-and-answer set comprising a question and a plurality of answer choices;
a multi-layer transformer module for iteratively decoding the output of the embedding module based on the generated tokens related to the structured interpretation text from the previous iteration to generate an interpretation text for inferring which answer selection is correct for the question, wherein the structured interpretation text from the previous iteration comprises the interpretation text generated by the human annotator; and
a classification module for generating a prediction of which answer selection is correct for the question using the generated interpretation text.
9. The system of claim 8, wherein the structured source text of the question-and-answer set comprises text in natural language form.
10. The system of claim 8 or 9, wherein the embedding module and the multilayer transformer module comprise at least a portion of a neural network.
11. The system of any of claims 8-10, wherein the question, the plurality of answer selections, and the generated interpretation text separated by separators are provided to the classification module.
12. The system of any of claims 8-11, wherein the embedding module and the multilayer transformer module comprise at least a portion of a natural language model.
13. The system of any of claims 8-12, wherein the classification module comprises a multilayer transformer encoder.
14. A non-transitory machine-readable medium comprising executable code that, when executed by one or more processors associated with a computer, is adapted to cause the one or more processors to perform a method comprising:
encoding and embedding, by an embedding module, structured source text for a question and answer set, the question and answer set comprising a question and a plurality of answer choices;
iteratively decoding, by the multi-layer transformer module, an output of the embedding module based on the generated tokens related to the structured interpretation text from the previous iteration, including the interpretation text generated by the human annotator, to generate interpretation text for inferring which answer selection is correct for the question;
providing the generated interpretation text to a classification module; and
using the generated interpretation text, a prediction is generated at the classification module which answer selection is correct for the question.
15. The non-transitory machine-readable medium of claim 14, wherein the structured source text of the question-and-answer set comprises text in natural language.
16. The non-transitory machine-readable medium of claim 14 or 15, comprising executable code that when executed by the one or more processors is adapted to cause the one or more processors to collect the structured interpretation text from the human annotator.
17. The non-transitory machine-readable medium of any of claims 14-16, comprising executable code that when executed by the one or more processors is adapted to cause the one or more processors to:
providing the human annotator with a set of training questions and answers; and
receiving the structured interpretation text from the human annotator in response to the training set of questions and answers.
18. The non-transitory machine-readable medium of any of claims 14-17, comprising executable code that when executed by the one or more processors is adapted to cause the one or more processors to provide the set of questions and answers to the classification module, wherein the questions, the plurality of answer selections, and the generated interpretation text are separated by separators when provided to the classification module.
19. The non-transitory machine-readable medium of any of claims 14-18, wherein the embedding module and the multilayer transformer module comprise at least a portion of a natural language model.
20. The non-transitory machine-readable medium of any of claims 14-19, wherein the classification module comprises a multi-layer transformer encoder.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962813697P | 2019-03-04 | 2019-03-04 | |
| US62/813,697 | 2019-03-04 | ||
| US16/393,801 US11366969B2 (en) | 2019-03-04 | 2019-04-24 | Leveraging language models for generating commonsense explanations |
| US16/393,801 | 2019-04-24 | ||
| PCT/US2020/019453 WO2020180518A1 (en) | 2019-03-04 | 2020-02-24 | Leveraging language models for generating commonsense explanations |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113519001A true CN113519001A (en) | 2021-10-19 |
| CN113519001B CN113519001B (en) | 2024-08-09 |
Family
ID=72334624
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202080018455.XA Active CN113519001B (en) | 2019-03-04 | 2020-02-24 | Generating common sense interpretations using language models |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11366969B2 (en) |
| EP (1) | EP3935573A1 (en) |
| JP (1) | JP7158598B2 (en) |
| CN (1) | CN113519001B (en) |
| WO (1) | WO2020180518A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023077990A1 (en) * | 2021-11-05 | 2023-05-11 | International Business Machines Corporation | Computer assisted answering boolean questions with evidence |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10817650B2 (en) | 2017-05-19 | 2020-10-27 | Salesforce.Com, Inc. | Natural language processing using context specific word vectors |
| US10963652B2 (en) | 2018-12-11 | 2021-03-30 | Salesforce.Com, Inc. | Structured text translation |
| US11822897B2 (en) | 2018-12-11 | 2023-11-21 | Salesforce.Com, Inc. | Systems and methods for structured text translation with tag alignment |
| US11003867B2 (en) | 2019-03-04 | 2021-05-11 | Salesforce.Com, Inc. | Cross-lingual regularization for multilingual generalization |
| GB201911760D0 (en) | 2019-08-16 | 2019-10-02 | Eigen Tech Ltd | Training and applying structured data extraction models |
| US11922303B2 (en) | 2019-11-18 | 2024-03-05 | Salesforce, Inc. | Systems and methods for distilled BERT-based training model for text classification |
| US12086539B2 (en) | 2019-12-09 | 2024-09-10 | Salesforce, Inc. | System and method for natural language processing using neural network with cross-task training |
| US11487999B2 (en) | 2019-12-09 | 2022-11-01 | Salesforce.Com, Inc. | Spatial-temporal reasoning through pretrained language models for video-grounded dialogues |
| CA3163943A1 (en) * | 2020-01-07 | 2021-07-15 | Raymond Li | Recommendation method and system |
| US11669745B2 (en) | 2020-01-13 | 2023-06-06 | Salesforce.Com, Inc. | Proposal learning for semi-supervised object detection |
| US11562147B2 (en) | 2020-01-23 | 2023-01-24 | Salesforce.Com, Inc. | Unified vision and dialogue transformer with BERT |
| US11948665B2 (en) | 2020-02-06 | 2024-04-02 | Salesforce, Inc. | Systems and methods for language modeling of protein engineering |
| US11893060B2 (en) * | 2020-02-06 | 2024-02-06 | Naver Corporation | Latent question reformulation and information accumulation for multi-hop machine reading |
| US11328731B2 (en) | 2020-04-08 | 2022-05-10 | Salesforce.Com, Inc. | Phone-based sub-word units for end-to-end speech recognition |
| US12299982B2 (en) | 2020-05-12 | 2025-05-13 | Salesforce, Inc. | Systems and methods for partially supervised online action detection in untrimmed videos |
| US11669699B2 (en) | 2020-05-31 | 2023-06-06 | Saleforce.com, inc. | Systems and methods for composed variational natural language generation |
| US12265909B2 (en) | 2020-06-01 | 2025-04-01 | Salesforce, Inc. | Systems and methods for a k-nearest neighbor based mechanism of natural language processing models |
| US11720559B2 (en) | 2020-06-02 | 2023-08-08 | Salesforce.Com, Inc. | Bridging textual and tabular data for cross domain text-to-query language semantic parsing with a pre-trained transformer language encoder and anchor text |
| US11321329B1 (en) * | 2020-06-24 | 2022-05-03 | Amazon Technologies, Inc. | Systems, apparatuses, and methods for document querying |
| US20220050877A1 (en) | 2020-08-14 | 2022-02-17 | Salesforce.Com, Inc. | Systems and methods for query autocompletion |
| US11934952B2 (en) | 2020-08-21 | 2024-03-19 | Salesforce, Inc. | Systems and methods for natural language processing using joint energy-based models |
| US11934781B2 (en) | 2020-08-28 | 2024-03-19 | Salesforce, Inc. | Systems and methods for controllable text summarization |
| US20220129637A1 (en) * | 2020-10-23 | 2022-04-28 | International Business Machines Corporation | Computerized selection of semantic frame elements from textual task descriptions |
| US20220138559A1 (en) * | 2020-11-05 | 2022-05-05 | International Business Machines Corporation | Answer span correction |
| US11829442B2 (en) | 2020-11-16 | 2023-11-28 | Salesforce.Com, Inc. | Methods and systems for efficient batch active learning of a deep neural network |
| CN112612881B (en) * | 2020-12-28 | 2022-03-25 | 电子科技大学 | Chinese intelligent dialogue method based on Transformer |
| WO2022246162A1 (en) * | 2021-05-20 | 2022-11-24 | Ink Content, Inc. | Content generation using target content derived modeling and unsupervised language modeling |
| US11983777B1 (en) * | 2021-07-28 | 2024-05-14 | Massachusetts Mutual Life Insurance Company | Systems and methods for risk factor predictive modeling with model explanations |
| US20230289836A1 (en) * | 2022-03-11 | 2023-09-14 | Tredence Inc. | Multi-channel feedback analytics for presentation generation |
| KR20240036790A (en) * | 2022-09-14 | 2024-03-21 | 현대자동차주식회사 | Learning method of maching reading comprehension model, computer-readable recording medium and question answering system |
| WO2025038647A1 (en) * | 2023-08-16 | 2025-02-20 | Visa International Service Association | Large language model reasoning via querying database |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106383835A (en) * | 2016-08-29 | 2017-02-08 | 华东师范大学 | Natural language knowledge exploration system based on formal semantics reasoning and deep learning |
Family Cites Families (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140108321A1 (en) * | 2012-10-12 | 2014-04-17 | International Business Machines Corporation | Text-based inference chaining |
| US9311301B1 (en) * | 2014-06-27 | 2016-04-12 | Digital Reasoning Systems, Inc. | Systems and methods for large scale global entity resolution |
| US11113598B2 (en) | 2015-06-01 | 2021-09-07 | Salesforce.Com, Inc. | Dynamic memory network |
| US20160350653A1 (en) | 2015-06-01 | 2016-12-01 | Salesforce.Com, Inc. | Dynamic Memory Network |
| US9760564B2 (en) * | 2015-07-09 | 2017-09-12 | International Business Machines Corporation | Extracting veiled meaning in natural language content |
| US20170032280A1 (en) | 2015-07-27 | 2017-02-02 | Salesforce.Com, Inc. | Engagement estimator |
| US20170140240A1 (en) | 2015-07-27 | 2017-05-18 | Salesforce.Com, Inc. | Neural network combined image and text evaluator and classifier |
| EP3335158B1 (en) | 2015-08-15 | 2019-07-24 | Salesforce.com, Inc. | Three-dimensional (3d) convolution with 3d batch normalization |
| US10796241B2 (en) * | 2015-10-30 | 2020-10-06 | International Business Machines Corporation | Forecastable supervised labels and corpus sets for training a natural-language processing system |
| US10565493B2 (en) | 2016-09-22 | 2020-02-18 | Salesforce.Com, Inc. | Pointer sentinel mixture architecture |
| US11042796B2 (en) | 2016-11-03 | 2021-06-22 | Salesforce.Com, Inc. | Training a joint many-task neural network model using successive regularization |
| US10963782B2 (en) | 2016-11-04 | 2021-03-30 | Salesforce.Com, Inc. | Dynamic coattention network for question answering |
| US20180129937A1 (en) | 2016-11-04 | 2018-05-10 | Salesforce.Com, Inc. | Quasi-recurrent neural network |
| US10558750B2 (en) | 2016-11-18 | 2020-02-11 | Salesforce.Com, Inc. | Spatial attention model for image captioning |
| US11354565B2 (en) | 2017-03-15 | 2022-06-07 | Salesforce.Com, Inc. | Probability-based guider |
| US10565318B2 (en) | 2017-04-14 | 2020-02-18 | Salesforce.Com, Inc. | Neural machine translation with latent tree attention |
| US10474709B2 (en) | 2017-04-14 | 2019-11-12 | Salesforce.Com, Inc. | Deep reinforced model for abstractive summarization |
| US11386327B2 (en) | 2017-05-18 | 2022-07-12 | Salesforce.Com, Inc. | Block-diagonal hessian-free optimization for recurrent and convolutional neural networks |
| US10747761B2 (en) | 2017-05-18 | 2020-08-18 | Salesforce.Com, Inc. | Neural network based translation of natural language queries to database queries |
| US10817650B2 (en) | 2017-05-19 | 2020-10-27 | Salesforce.Com, Inc. | Natural language processing using context specific word vectors |
| US12014257B2 (en) | 2017-05-19 | 2024-06-18 | Salesforce, Inc. | Domain specific language for generation of recurrent neural network architectures |
| US20190130896A1 (en) | 2017-10-26 | 2019-05-02 | Salesforce.Com, Inc. | Regularization Techniques for End-To-End Speech Recognition |
| US10573295B2 (en) | 2017-10-27 | 2020-02-25 | Salesforce.Com, Inc. | End-to-end speech recognition with policy learning |
| US11928600B2 (en) | 2017-10-27 | 2024-03-12 | Salesforce, Inc. | Sequence-to-sequence prediction using a neural network model |
| US11604956B2 (en) | 2017-10-27 | 2023-03-14 | Salesforce.Com, Inc. | Sequence-to-sequence prediction using a neural network model |
| US10592767B2 (en) | 2017-10-27 | 2020-03-17 | Salesforce.Com, Inc. | Interpretable counting in visual question answering |
| US11562287B2 (en) | 2017-10-27 | 2023-01-24 | Salesforce.Com, Inc. | Hierarchical and interpretable skill acquisition in multi-task reinforcement learning |
| US11170287B2 (en) | 2017-10-27 | 2021-11-09 | Salesforce.Com, Inc. | Generating dual sequence inferences using a neural network model |
| US10346721B2 (en) | 2017-11-01 | 2019-07-09 | Salesforce.Com, Inc. | Training a neural network using augmented training datasets |
| US10542270B2 (en) | 2017-11-15 | 2020-01-21 | Salesforce.Com, Inc. | Dense video captioning |
| US11276002B2 (en) | 2017-12-20 | 2022-03-15 | Salesforce.Com, Inc. | Hybrid training of deep networks |
| US11501076B2 (en) | 2018-02-09 | 2022-11-15 | Salesforce.Com, Inc. | Multitask learning as question answering |
| US11227218B2 (en) | 2018-02-22 | 2022-01-18 | Salesforce.Com, Inc. | Question answering from minimal context over documents |
| US10929607B2 (en) | 2018-02-22 | 2021-02-23 | Salesforce.Com, Inc. | Dialogue state tracking using a global-local encoder |
| US11106182B2 (en) | 2018-03-16 | 2021-08-31 | Salesforce.Com, Inc. | Systems and methods for learning for domain adaptation |
| US10783875B2 (en) | 2018-03-16 | 2020-09-22 | Salesforce.Com, Inc. | Unsupervised non-parallel speech domain adaptation using a multi-discriminator adversarial network |
| CN111727444A (en) * | 2018-05-18 | 2020-09-29 | 谷歌有限责任公司 | Universal converter |
-
2019
- 2019-04-24 US US16/393,801 patent/US11366969B2/en active Active
-
2020
- 2020-02-24 JP JP2021550225A patent/JP7158598B2/en active Active
- 2020-02-24 CN CN202080018455.XA patent/CN113519001B/en active Active
- 2020-02-24 EP EP20713455.2A patent/EP3935573A1/en not_active Ceased
- 2020-02-24 WO PCT/US2020/019453 patent/WO2020180518A1/en unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106383835A (en) * | 2016-08-29 | 2017-02-08 | 华东师范大学 | Natural language knowledge exploration system based on formal semantics reasoning and deep learning |
Non-Patent Citations (3)
| Title |
|---|
| LIN XIAO ET AL.: "Don’t just listen, use your imagination:Leveraging visual common sense for non-visual tasks", 《ARXIV》, pages 1 - 4 * |
| QING LI ET AL.: "VQA-E:Explaining, Elaborating, and Enhancing Your Answers for Visual Questions", 《ARXIV》, pages 4 * |
| 王国胤;李帅;杨洁;: "知识与数据双向驱动的多粒度认知计算", 西北大学学报(自然科学版), no. 04 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023077990A1 (en) * | 2021-11-05 | 2023-05-11 | International Business Machines Corporation | Computer assisted answering boolean questions with evidence |
| US12093657B2 (en) | 2021-11-05 | 2024-09-17 | International Business Machines Corporation | Computer assisted answering Boolean questions with evidence |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022522712A (en) | 2022-04-20 |
| US11366969B2 (en) | 2022-06-21 |
| CN113519001B (en) | 2024-08-09 |
| JP7158598B2 (en) | 2022-10-21 |
| US20200285704A1 (en) | 2020-09-10 |
| WO2020180518A1 (en) | 2020-09-10 |
| EP3935573A1 (en) | 2022-01-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113519001A (en) | Generating common sense interpretations using language models | |
| US11580975B2 (en) | Systems and methods for response selection in multi-party conversations with dynamic topic tracking | |
| US11562147B2 (en) | Unified vision and dialogue transformer with BERT | |
| Rocktäschel et al. | Reasoning about entailment with neural attention | |
| Lu et al. | Hierarchical question-image co-attention for visual question answering | |
| Sojasingarayar | Seq2seq ai chatbot with attention mechanism | |
| US12086539B2 (en) | System and method for natural language processing using neural network with cross-task training | |
| CN111699498A (en) | Multitask learning as question and answer | |
| US20230394328A1 (en) | Prompting Machine-Learned Models Using Chains of Thought | |
| US20160217129A1 (en) | Method and Apparatus for Determining Semantic Matching Degree | |
| Le | A tutorial on deep learning part 1: Nonlinear classifiers and the backpropagation algorithm | |
| US10460039B2 (en) | Method for controlling identification and identification control apparatus | |
| CN106663221A (en) | Knowledge-graph biased classification for data | |
| US12346828B2 (en) | Image analysis by prompting of machine-learned models using chain of thought | |
| US11574190B2 (en) | Method and apparatus for determining output token | |
| US20230042327A1 (en) | Self-supervised learning with model augmentation | |
| CN115408502A (en) | Cognitive learning in a synchronous conference to generate scripts that simulate live agent actions | |
| Rouvier | Lia at semeval-2017 task 4: An ensemble of neural networks for sentiment classification | |
| Surendran et al. | Conversational AI-A retrieval based chatbot | |
| Tang et al. | Improving mild cognitive impairment prediction via reinforcement learning and dialogue simulation | |
| Zouidine et al. | Selective Reading for Arabic Sentiment Analysis | |
| Gummadi et al. | Analysis of machine learning in education sector | |
| Wu et al. | Actions as contexts | |
| Alghamdi | Solving Arabic Math Word Problems via Deep Learning | |
| CN119558372A (en) | Fine-tuning method, device, equipment, medium and product for generative model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Address after: California, USA Applicant after: Shuo Power Co. Address before: California, USA Applicant before: SALESFORCE.COM, Inc. |
|
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |