US11409751B2 - Providing answers to questions using hypothesis pruning - Google Patents
Providing answers to questions using hypothesis pruning Download PDFInfo
- Publication number
- US11409751B2 US11409751B2 US16/267,688 US201916267688A US11409751B2 US 11409751 B2 US11409751 B2 US 11409751B2 US 201916267688 A US201916267688 A US 201916267688A US 11409751 B2 US11409751 B2 US 11409751B2
- Authority
- US
- United States
- Prior art keywords
- candidate answers
- candidate
- group
- filter
- answer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active, expires
Links
- 238000013138 pruning Methods 0.000 title 1
- 238000000034 method Methods 0.000 claims abstract description 54
- 238000001914 filtration Methods 0.000 claims abstract description 34
- 238000012545 processing Methods 0.000 claims description 56
- 230000006870 function Effects 0.000 claims description 43
- 238000011045 prefiltration Methods 0.000 claims description 28
- 230000008569 process Effects 0.000 claims description 19
- 230000001419 dependent effect Effects 0.000 claims description 14
- 238000013442 quality metrics Methods 0.000 claims description 8
- 238000012360 testing method Methods 0.000 claims description 4
- 238000004519 manufacturing process Methods 0.000 claims 6
- 238000004590 computer program Methods 0.000 abstract description 8
- 238000004458 analytical method Methods 0.000 description 58
- 238000013499 data model Methods 0.000 description 9
- 238000003058 natural language processing Methods 0.000 description 9
- 230000037361 pathway Effects 0.000 description 8
- 238000010586 diagram Methods 0.000 description 7
- 230000014509 gene expression Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 6
- 230000003993 interaction Effects 0.000 description 5
- 238000007477 logistic regression Methods 0.000 description 5
- 238000007726 management method Methods 0.000 description 5
- 239000003607 modifier Substances 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000010801 machine learning Methods 0.000 description 4
- 230000000007 visual effect Effects 0.000 description 4
- 235000006719 Cassia obtusifolia Nutrition 0.000 description 3
- 235000014552 Cassia tora Nutrition 0.000 description 3
- 239000008186 active pharmaceutical agent Substances 0.000 description 3
- 238000011835 investigation Methods 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- RBSXHDIPCIWOMG-UHFFFAOYSA-N 1-(4,6-dimethoxypyrimidin-2-yl)-3-(2-ethylsulfonylimidazo[1,2-a]pyridin-3-yl)sulfonylurea Chemical compound CCS(=O)(=O)C=1N=C2C=CC=CN2C=1S(=O)(=O)NC(=O)NC1=NC(OC)=CC(OC)=N1 RBSXHDIPCIWOMG-UHFFFAOYSA-N 0.000 description 2
- 244000201986 Cassia tora Species 0.000 description 2
- 241001465805 Nymphalidae Species 0.000 description 2
- 241000845082 Panama Species 0.000 description 2
- 238000005352 clarification Methods 0.000 description 2
- 238000000354 decomposition reaction Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000011143 downstream manufacturing Methods 0.000 description 2
- 230000005055 memory storage Effects 0.000 description 2
- 239000008267 milk Substances 0.000 description 2
- 235000013336 milk Nutrition 0.000 description 2
- 210000004080 milk Anatomy 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 235000013379 molasses Nutrition 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 230000003068 static effect Effects 0.000 description 2
- 244000277285 Cassia obtusifolia Species 0.000 description 1
- 229930186657 Lat Natural products 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 201000000839 Vitamin K Deficiency Bleeding Diseases 0.000 description 1
- 206010047634 Vitamin K deficiency Diseases 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000013145 classification model Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 208000016794 vitamin K deficiency hemorrhagic disease Diseases 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24575—Query processing with adaptation to user needs using context
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/248—Presentation of query results
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
Definitions
- This invention generally relates to information retrieval, and more specifically, to question answering. Even more specifically, embodiments of the invention relate to query/answer systems and methods implementing parallel analysis for providing answers to questions by generating and evaluating multiple candidate answers.
- QA question answering
- NLP complex natural language processing
- Search collections vary from small local document collections, to internal organization documents, to compiled newswire reports, to the world wide web.
- Closed-domain question answering deals with questions under a specific domain (for example, medicine or automotive maintenance), and can be seen as an easier task because NLP systems can exploit domain-specific knowledge frequently formalized in ontologies.
- closed-domain might refer to a situation where only a limited type of questions are accepted, such as questions asking for descriptive rather than procedural information.
- Open-domain question answering deals with questions about nearly everything, and can only rely on general ontologies and world knowledge. Open-domainQ/A systems, though, usually have much more data available from which to extract the answer.
- Access to information is currently dominated by two paradigms: a database query that answers questions about what is in a collection of structured records; and a search that delivers a collection of document links in response to a query against a collection of unstructured data (text, html etc.).
- One major challenge in such information query paradigms is to provide a computer program capable of answering factual questions based on information included in a large collection of documents (of all kinds, structured and unstructured). Such questions can range from broad such as “what are the risk of vitamin K deficiency” to narrow such as “when and where was Hillary Clinton's father born”.
- User interaction with such a computer program could be either a single user-computer exchange or a multiple turn dialog between the user and the computer system.
- Such dialog can involve one or multiple modalities (text, voice, tactile, gesture etc.).
- Examples of such interaction include a situation where a cell phone user is asking a question using voice and is receiving an answer in a combination of voice, text and image (e.g. a map with a textual overlay and spoken (computer generated) explanation.
- Another example would be a user interacting with a video game and dismissing or accepting an answer using machine recognizable gestures or the computer generating tactile output to direct the user.
- Embodiments of the invention provide a method, system and computer program product for generating answers to questions.
- the method comprises receiving an input query, conducting a search through one or more data sources to identify a plurality of candidate answers to the input query, and providing each of the candidate answers with a preliminary score based on one or more defined criterion.
- the method further comprises filtering out any of the candidate answers with a preliminary score that does not satisfy a defined condition.
- the candidate answers having preliminary scores that satisfy said defined condition form a subset of the candidate answers.
- Each of the candidate answers in this subset is processed to produce a plurality of further scores for each of these candidate answers.
- a candidate ranking function is applied to these further scores to determine a ranking for each of the candidate answers in the subset of candidate answers; and after the applying this candidate ranking function, one or more of the candidate answers are selected as one or more final answers to the input query.
- each of the candidate answers in the subset of candidate answers is processed by using a supporting passage retrieval process to identify passages in which said each of the candidate answers occur.
- the subset of candidate answers is sent from the supporting passage retrieval process to a candidate ranking function module, and this module is used to apply the candidate ranking function to the candidate answers in the subset of candidate answers.
- any filtered out candidate answers may also be sent to the candidate ranking function, and this module may also be used to apply the candidate ranking function to any filtered out candidate answers.
- the candidate answers selected as the one or more final answers may be selected from among the candidate answers in the subset of candidate answers as well as any filtered out candidate answers.
- a filtering module is used to filter out any of the candidate answers with a preliminary score that does not satisfy the defined criterion includes passing the candidate answers through a filtering module to perform said filtering. Any such filtered out candidate answers are sent to the candidate ranking function module in a manner by-passing the supporting passage retrieval process.
- each of the candidate answers in the subset of candidate answers is processed using a context independent candidate answer process to obtain one or more post-filtering scores for said each of the candidate answers.
- each of the candidate answers of the subset of candidate answers are ranked based on the post-filtering scores for said each of the candidate answers.
- each of the candidate answers is provided with the preliminary score by using a logistics regression model to score said each of the candidate answers.
- any of the candidate answers with a preliminary score below a defined threshold are filtered out.
- this defined threshold is established to obtain a desired tradeoff between computational cost and a quality metric for the final answer.
- the defined threshold is determined by running a test on a given set of data to obtain this desired tradeoff.
- only a subset of the candidate answers are used for finding supporting evidence. This subset may not include all of the candidate answers.
- the subset of candidate answers to use for supporting passage retrieval is identified by the following procedure:
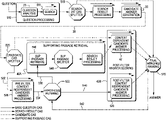
- FIG. 1 shows a system diagram depicting a high level logical architecture and question/answering method for an embodiment of the present invention
- FIG. 2 shows a variant of the architecture of FIG. 1 , where the Evidence Gathering module includes two submodules: Supporting Passage Retrieval and Candidate Answer Scoring.
- FIG. 3 shows a more detailed diagram of the Query Analysis and the Candidate Answer Generation modules of FIG. 1 .
- FIG. 4 shows a more detailed diagram of the Candidate Answer Scoring and the Answer Ranking Modules of FIGS. 1 and 2 .
- FIG. 5 is an example flow diagram depicting method steps for processing questions and providing answers according to an embodiment of the invention.
- FIG. 6 depicts an aspect of a UIMA framework implementation for providing one type of analysis engine for processing CAS data structures.
- the words “question” and “query,” and their extensions, are used interchangeably and refer to the same concept, namely a request for information. Such requests are typically expressed in an interrogative sentence, but they can also be expressed in other forms, for example as a declarative sentence providing a description of an entity of interest (where the request for the identification of the entity can be inferred from the context).
- Structured information (from “structured information sources”) is defined herein as information whose intended meaning is unambiguous and explicitly represented in the structure or format of the data (e.g., a database table).
- Unstructured information (from “unstructured information sources”) is defined herein as information whose intended meaning is only implied by its content (e.g., a natural language document).
- “Semi structured information” refers to data having some of its meaning explicitly represented in the format of the data, for example a portion of the document can be tagged as a “title”.
- FIG. 1 shows a system diagram depicting a high-level logical architecture 10 and methodology of an embodiment of the present invention.
- the architecture 10 includes a Query Analysis module 20 implementing functions for receiving and analyzing a user query or question.
- a “user” refers to a person or persons interacting with the system
- the term “user query” refers to a query (and its context) 19 posed by the user.
- the term “user” refers to a computer system 22 generating a query by mechanical means
- the term “user query” refers to such a mechanically generated query and its context 19 ′.
- a candidate answer generation module 30 is provided to implement a search for candidate answers by traversing structured, semi structured and unstructured sources contained in a Primary Sources module 11 and in an Answer Source Knowledge Base module 21 containing collections of relations and lists extracted from primary sources. All the sources of information can be locally stored or distributed over a network, including the Internet.
- the Candidate Answer generation module 30 generates a plurality of output data structures containing candidate answers based upon the analysis of retrieved data.
- FIG. 1 one embodiment is depicted that includes an Evidence Gathering module 50 interfacing with the primary sources 11 and knowledge base 21 for concurrently analyzing the evidence based on passages having candidate answers, and scoring each of the candidate answers as parallel processing operations.
- the architecture may be employed utilizing the Common Analysis System (CAS) candidate answer structures, and implementing Supporting Passage Retrieval as will be described in greater detail herein below.
- CAS Common Analysis System
- the Answer Source Knowledge Base 21 may comprise one or more databases of structured or semi-structured sources (pre-computed or otherwise) comprising collections of relations (e.g., Typed Lists).
- the Answer Source knowledge base may comprise a database stored in a memory storage system, e.g., a hard drive.
- An Answer Ranking module 60 provides functionality for ranking candidate answers and determining a response 99 that is returned to a user via a user's computer display interface (not shown) or a computer system 22 .
- the response may be an answer, or an elaboration of a prior answer or a request for clarification in response to a question—when a high quality answer to the question is not found.
- both an input query and a generated query response may be provided in accordance with one or more of multiple modalities including text, audio, image, video, tactile or gesture.
- FIGS. 1 and 2 may be local, on a server, or server cluster, within an enterprise, or alternately, may be distributed with or integral with or otherwise operate in conjunction with a public or privately available search engine in order to enhance the question answer functionality in the manner as described.
- embodiments of the invention may be provided as a computer program product comprising instructions executable by a processing device, or as a service deploying the computer program product.
- the architecture employs a search engine (a document retrieval system) as a part of Candidate Answer Generation module 30 which may be dedicated to the Internet, a publicly available database, a web-site (e.g., IMDB.com) or a privately available database.
- Databases can be stored in any storage system, e.g., a hard drive or flash memory, and can be distributed over a network or not.
- CAS Common Analysis System
- UIMA Unstructured Information Management Architecture
- CAS supports data modeling via a type system independent of programming language, provides data access through a powerful indexing mechanism, and provides support for creating annotations on text data, such as described in (http://www.research.ibm.com/journal/sj/433/gotz.html) incorporated by reference as if set forth herein.
- CAS also allows for multiple definitions of the linkage between a document and its annotations, as is useful for the analysis of images, video, or other non-textual modalities.
- the UIMA may be provided as middleware for the effective management and interchange of unstructured information over a wide array of information sources.
- the architecture generally includes a search engine, data storage, analysis engines containing pipelined document annotators and various adapters.
- the UIMA system, method and computer program may be used to generate answers to input queries.
- the method includes inputting a document and operating at least one text analysis engine that comprises a plurality of coupled annotators for tokenizing document data and for identifying and annotating a particular type of semantic content. Thus it can be used to analyze a question and to extract entities as possible answers to a question from a collection of documents.
- CAS Common Analysis System
- the “Query Analysis” module 20 receives an input that comprises the query 19 entered, for example, by a user via their web-based browser device.
- An input query 19 may comprise a string such as “Who was the tallest American president?”.
- a question may comprise of a string and an implicit context, e.g., “Who was the shortest?”.
- context may range from a simple another string e.g. “American presidents” or “Who was the tallest American president?” to any data structure, e.g. all intermediate results of processing of the previous strings—a situation arising e.g., in a multiple turn dialog.
- the input query is received by the Query Analysis module 20 which includes, but is not limited to, one or more the following sub-processes: Parse and Predicate Argument Structure block 202 ; a Focus Segment, Focus and Modifiers block 204 ; Lexical Answer Type block 206 ; Question Decomposition block 208 ; a Lexical and Semantic Relations module 210 ; a Question Classifier block 212 ; and a Question Difficulty module 214 .
- the Parse and Predicate Argument Structure block 202 implements functions and programming interfaces for decomposing an input query into its grammatical and semantic components, e.g., noun phrases, verb phrases and predicate/argument structure.
- An (English Slot Grammar) ESG-type parser may be used to implement block 202 .
- the Focus Segment, Focus & Modifiers block 204 is provided to compute the focus and focus modifiers of the question, and is further described below.
- the Lexical Answer Type (LAT) block 206 implements functions and programming interfaces to provide additional constraints on the answer type (Lexical) as will be described in greater detail herein below.
- the Question decomposition block 208 implements functions and programming interfaces for analyzing the input question to determine the sets of constraints specified by the question about the target answer.
- constraints may relate to one another: 1) Nested Constraints; 2) Redundant Constraints; and 3) Triangulation.
- an answer to an “inner” question instantiates an “outer” question. For example, “Which Florida city was named for the general who led the fight to take Florida from the Spanish?”. With redundant constraints, one constraint uniquely identifies the answer. For instance, “This tallest mammal can run at 30 miles per hour. Which is it?”.
- each constraint With triangulation, each constraint generates a set of answers and the correct answer is the one answer in common in the two (or more) sets. For example, in a “puzzle”-style question “What is a group of things of the same kind, or scenery constructed for a theatrical performance”.
- the Lexical and Semantic Relations module 210 is provided to detect lexical and semantic relations in the query (e.g., predicate-argument relations) as is the Question Classification block 212 that may employ topic classifiers providing information addressing, e.g., what is the question about?
- the Question Difficulty module 214 executes methods providing a way to ascertain a question's difficulty, e.g., by applying readability matrix to the question. It is understood that one or more of the query/question analysis processing blocks shown in FIG. 3 may be selected for a particular implementation.
- the Parse and Predicate Argument Structure block 202 implements functions and programming interfaces for decomposing an input query into its grammatical components by performing a Lexical processing and a syntactic and predicate argument structure analysis as known in the art. For an example query:
- the Parse and Predicate Arguments block 202 will produce an example parse search results tree structure below with e X providing an index into the tree, e.g., the “become” word is e8 (the 8 th structure of the results tree, and e7 indexes the 7 th word of the results tree structure) where 7 represents the word (“city”) that is the first argument of “become” and e13 (indexes the 13 th word of the results tree structure) is the “producer” which is the second argument of “become” in the semantic structure depicted:
- the Focus Segment, Focus and Modifiers block 204 detects a Focus Segment which is the text span in the question that the correct answer replaces. For example, in the following query, the italicized words represent the focus segment in the query:
- Example patterns include, e.g., a Noun Phrase; “what/which/this/these X”, where X is another object(s); “who/what/when/where/why/this/these”; a Pronoun without a referent.
- An example of a pronoun pattern with the pronoun words italicized is as follows:
- LAT is the question terms that identify the semantic type of the correct answer.
- the italicized words in the following passage represent the LAT in the following query:
- LATs may include modifiers if they change the meaning.
- the italicized words represent the LAT in the following query:
- an output 29 of the Question/Query analysis block 20 comprises a query analysis result data structure (CAS structure).
- the output data structure Question/Query analysis block 20 and the candidate answer generation block 30 may be implemented to pass the data among the modules, in accordance with the UIMA Open Source platform.
- the “Candidate Answer Generation” module 30 receives the CAS-type query results data structure 29 output from the Question/Query analysis block 20 , and generates a collection of candidate answers based on documents stored in Primary Sources 11 and in Answer Source KB 21 .
- the “Candidate Answer Generation” module 30 includes, but is not limited to, one or more of the following functional sub-processing modules: A Term Weighting & Query Expansion module 302 ; a Document Titles (Document Retrieval in Title Sources) module 304 ; an Entities From Passage Retrieval module 308 ; and an Entities from Structural Sources K.B. module 310 .
- the Term Weighting and Query Expansion module 302 implements functions for creating a query against modules 11 and 21 (part of query generation) with an embodiment implementing query expansion (see, e.g., http://en.wikipedia.org/wiki/Query_expansion).
- the Document Titles (Document Retrieval in Title Sources) module 304 implements functions for detecting a candidate answer (from sources 11 and 21 ).
- the Entities From Passage Retrieval module 308 implements functions for detecting a candidate answer in textual passages, e.g. based on grammatical and semantic structures of the passages and the query.
- the Entities from Structured Sources module KB 310 implements functions for retrieving a candidate answer based on matches between the relations between the entities in the query and the entities in Answer Source KB 21 (implemented e.g. as an SQL query).
- a query is created and run against all of the structured and unstructured primary data sources 11 in the (local or distributed) sources database or like memory storage device(s).
- This query may be run against the structured (KB), semi-structured (e.g., Wikipedia, IMDB databases, a collection of SEC filings in XBRL, etc.), or unstructured data (text repositories) to generate a candidate answer list 39 (also as a CAS, or an extension of prior CAS).
- the query is run against a local copy of the listed primary source databases, or may access the publically available public database sources.
- not all the terms from the query need to be used for searching the answer—hence the need for creating the query based on results of the query analysis. For example, to answer the question “five letter previous capital of Poland,” the terms “five letter” should not be part of the query.
- the Lexical and Semantic Relations in Passage module 402 implements functions computing how well semantic (predicate/argument) relations in the candidate answer passages are satisfied (part of answer scoring).
- the Text Alignment module 405 implements functions for aligning the query (or portions thereof) and the answer passage and computing the score describing the degree of alignment, e.g., when aligning answers in a quotation.
- the Query Term Matching in Passage module 407 implements functions for relating how well a passage in the query matches to terms in the candidate answer passages (part of answer scoring).
- the Grammatical Relations block 410 implements functions for detecting a grammatical relations among candidate answers which can be subsumed under the Lexical & Semantic Relations in Passage module 402 .
- multiple parallel operating modules may be implemented to compute the scores of the candidate answers with the scores provided in CAS-type data structures 59 based on the above criteria. For instance, does the answer satisfy similar lexical and semantic relations (e.g. for a query about an actress starring in a movie, is the answer a female, and does the candidate satisfy actor-in-movie relation?), how well do the answer and the query align, how well do the terms match and do the terms exist in similar order.
- similar lexical and semantic relations e.g. for a query about an actress starring in a movie, is the answer a female, and does the candidate satisfy actor-in-movie relation?
- multiple modules are used to process different candidate answers and, thus, potentially provide many scores in accordance with the number of potential scoring modules.
- the “Answer Ranking” module 60 receives a plurality of CAS-type data structures 59 output from the Evidence Gathering block 50 (which includes implementing SPR 40 A and Candidate Answer Scoring 40 B), and generates a score for each received candidate answer.
- FIG. 4 shows a machine learning implementation where the “Answer Ranking” module 60 includes a trained model component 71 produced using a machine learning techniques from prior data.
- the prior data may encode information on features of candidate answers, the features of passages the candidate answers come in, the scores given to the candidate answers by Candidate Answer Scoring modules 40 B, and whether the candidate answer was correct or not.
- the machine learning algorithms can be applied to the entire content of the CASes together with the information about correctness of the candidate answer. Such prior data is readily available for instance in technical services support functions, or in more general settings on the Internet, where many websites list questions with correct answers.
- the model encodes a prediction function which is its input to the “Learned Feature Combination” module 73 .
- the learned feature combination sub-block 73 applies the prediction function produced by the Trained Model 71 , and for example it implements methods that weight the scores of candidate answers based on the trained model.
- An example implementation of the training block 71 and of Learned Feature Combination 73 may be found in the reference to Ittycheriah, A.
- a two-part task is implemented to: (1) identify a best answer among candidates, and (2) determine a confidence in that best answer.
- each question-candidate pair comprises an instance, and scores are obtained from a wide range of features, e.g., co-occurrence of answer and query terms, whether a candidate matches answer type, and search engine rank.
- scores are obtained from a wide range of features, e.g., co-occurrence of answer and query terms, whether a candidate matches answer type, and search engine rank.
- scores such as shown in the Table 1 below are generated based on but not limited to: Type Analysis, Alignment, Search Engine Rank, etc.
- TypeAgreement is the score for whether the lexical form of the candidate answer in the passage corresponds to the lexical type of the entity of interest in the question.
- Textual Alignment scores the alignment between question and answer passage.
- candidate answers are represented as instances according to their answer scores.
- a classification model 71 is trained over instances (based on prior data) with each candidate answer being classified as true/false for the question (using logistic regression or linear regression function or other types of prediction functions as known in the art).
- This model is now applied, and candidate answers are ranked according to classification score with the classification score used as a measure of answer confidence, that is, possible candidate answers are compared and evaluated by applying the prediction function to the complete feature set or subset thereof. If the classification score is higher than a threshold, this answer is deemed as an acceptable answer.
- the prediction function Score
- FIG. 5 is a block diagram 500 depicting system operation.
- a query is received by the system programmed to perform the steps of the invention.
- the set of instructions are executed in a computing environment comprising one or more processors or computing devices.
- the query is analyzed and parsed into elements suitable for searching by the search engine 511 (performing the information retrieval function of module 30 in FIGS. 1 and 2 ).
- Unstructured Information Management Architecture (UIMA) framework is an open, industrial-strength, scalable and extensible platform for building analytic applications or search solutions that process text or other unstructured information to find the latent meaning, relationships and relevant facts buried within (http://incubator.apache.org/uima/).
- the type system has a few basic design points.
- All processing results may be added to the original CAS (with intermediate results carrying the way through to the end of processing) and the final answer generated by the system is posted as an annotation in the CAS.
- the data model includes a base annotation type that many of the types extend the uima.tcas.Annotation (see http://incubator.apache.org/UIMA).
- Each class e.g., an annotator
- the base Question annotation type is defined to optionally include any associated meta-data such as the source of the question (TREC, technical support, TV show, etc.), prior dialog, or other contextual information (for example, about information contained in the input expressed in other modalities).
- the question type can be further specialized into example subtypes modeling questions that Question which class defines a Type (i.e., question type, for example, one of FACTOID, LIST, DEFINITION, OTHER, OPINION or UNCLASSIFIED question types).
- question type for example, one of FACTOID, LIST, DEFINITION, OTHER, OPINION or UNCLASSIFIED question types.
- NLP Natural Language Processing
- Natural language processing typically includes syntactic processing (e.g. using the ESG parser) and derivation of predicate-argument structure. This processing is performed in accordance with the standard UIMA fashion, where the NLP stack is run as an aggregate analysis engine on the CAS.
- all of the NLP stack results are added to the CAS as annotations extending Hutt and ESG type systems.
- the question analysis components are run, which include question classification, answer type detection, and focus identification, for example, as shown in the query analysis block of FIG. 3 .
- the question may be classified based on question types (metadata), each of which may require special downstream processing.
- the result of this classification may be stored in a QClass annotation:
- Example downstream processing may include processing a puzzle question (where getting the answer requires synthesis information from multiple sources, inference, etc.); an audio_visual question that requires audio/visual processing; a simple_factoid question with quotes, or named entities, etc.; a FACTOID about a fact that can be “looked up”; and a DEFINITION that contains a definition of the answer and where the words defined by the question are expected as an answer.
- a puzzle question where getting the answer requires synthesis information from multiple sources, inference, etc.
- an audio_visual question that requires audio/visual processing
- a simple_factoid question with quotes, or named entities, etc. a simple_factoid question with quotes, or named entities, etc.
- FACTOID about a fact that can be “looked up”
- DEFINITION that contains a definition of the answer and where the words defined by the question are expected as an answer.
- the typical question analysis processes shown in FIG. 3 produces several annotations, including the focus, answer type, semantic role labels, and constraints, and marks any portion of the question that represents a definition.
- the Question Analysis component 510 of FIG. 5 will create an instance of the annotation, set the span over the question text (if appropriate), and set any other features in the annotation. Note that there may be multiple instances of these annotations.
- the question and the results of question analysis are used to generate an abstract representation of the query, which for purposes of description, is referred to as the AbstractQuery.
- the abstract query represents all searchable keywords and phrases in the question, along with the semantic answer type (if it was detected).
- the abstract query is represented using the following types: a synonym (all query concepts underneath are synonyms of each other); a phrase (all query concepts in order are a phrase); a tie (an “or”, i.e., a disjunction of the argument nodes); a weight (the concepts underneath are weighted per the float stored in the operator); required (the concepts underneath are all required, if possible); and relation (the concepts underneath are below a relation, which is stored within the operator).
- search processing begins, and this may include searching primary structured and unstructured sources, e.g. Google, a local copy of Wikipedia, or database look-up.
- primary structured and unstructured sources e.g. Google, a local copy of Wikipedia, or database look-up.
- Each search engine has a query generator that generates an engine-specific query from the abstract query and formats it in the query syntax for the search engine.
- the search engine then processes the query and adds a search result hit-list to the CAS.
- a Search object contains the search engine query, an identifier for the search engine, and the search results.
- a search result is represented by a SearchResult object, which contains an identifier for the result (a URI), a score for the result, and the actual content of the result, i.e., the passage text, knowledge base tuple, etc.
- the SearchResult may be specialized for different kinds of search engines and corresponding search results.
- the Document object may be created to represent the result delivered by the search engine. This object may include a title of the document and a unique identifier for this document, and other data and meta-data.
- the passage object may be used with a search engine that returns passages. It may add to the document object the offset (e.g., a character offset of the start of this passage within the document that contains this passage, and a character offset of the end of this passage within the document that contains this passage) and passage length metadata for the passage hit.
- the data in the example CAS structure are output of the search results block of the question analysis processing step 510 and are about to be processed in parallel.
- a Search Hit CAS splitter mechanism 515 is used to initiate a parallel search for candidate answers.
- the search list search result passages
- the search list are distributed by the CAS splitter element 515 so that concurrent search results processing techniques are applied (work divided) to process each of the found search results and to perform candidate answer generation (in parallel) using the techniques described herein in the Candidate Answer Generation block 30 ( FIG. 3 ).
- candidate answers are identified in the search result.
- a candidate answer is represented at two different levels: a Candidate Answer Variant; and A Candidate Answers Canon.
- a CandidateAnswerVariant is a unique candidate answer string (possibly the result of some very simple normalization).
- a CandidateAnswerCanon is a canonicalized candidate answer that groups together semantically equivalent variants. Both of these types extend an abstract base class CandidateAnswer which class defines the candidate answer string and features associated with this candidate answer.
- a class for candidate answers provides the candidate answer string and features associated with this candidate answer.
- one or more of its subtypes may be instantiated.
- One sub-type includes a variant of a candidate answer class (CandidateAnswerVariant) defined that may have multiple occurrences, all of which are collected in a variant object and defines the occurrences of this variant.
- a CandidateAnswerOccurrence class is provided that annotates a span of text identified as a candidate answer and defines: (1) the manner in which covered text refers to some entity, e.g. NAME, PRONOUN, CITY; (2) the source of the candidate answer; (3) the character offset of the start of this candidate answer within the text of the source; and (4) the character offset of the end of this candidate answer within the text of the source.
- candidate answers are derived from document titles, and another method may derive a candidate answer from one or more elements in the candidate passage.
- Candidate answers can be normalized whereby several spelling variants can be identified in one canonical form.
- the data in the example CAS structure 39 output of the search results processing and candidate answer generation block 30 is again processed in parallel by a Candidate Answer CAS splitter mechanism 520 that is used to parallelize the candidate answers for further processing.
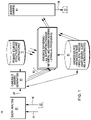
- a subset of the candidate answers to use for supporting passage retrieval at 40 A and 40 B is identified by the following procedure.
- Content independent scorers are run on the candidate answers (since these scorers do not require supporting passages).
- a scoring function e.g., a logistic regression model
- candidate answers with low scores for example, below a specified threshold
- the architecture of FIG. 5 is provided with a Hypothesis Filtering module 522 , a Pre-Filter Context Independent Candidate Answer Processing module 524 , and a Post-Filter Context Independent Candidate Answer Processing module 526 .
- Modules 524 and 526 may operate, in an embodiment of the invention, similar to context Independent Candidate Answer Processing module 43 of the above-identified U.S. patent application Ser. No. 12/152,411. Both modules 524 and 526 provide a score for a candidate answer independently of the passage in which the candidate answer is found—that is, independent of the content of the passage in which the candidate answer is found. For instance, if the candidate answer is obtained from the document title, the score will not be dependent on the content of the passage and is context independent.
- a pathway is provided in which the candidate CAS is sent from “candidate CAS Splitter” 520 to Pre-Filter Context Independent Candidate Answer Processing module 524 .
- a pathway 534 is also provided in which the candidate CAS is sent from the Pre-Filter Context Independent Candidate Answer Processing module 524 to the Hypothesis Filtering module 522 .
- a scoring function (e.g., a logistic regression model) is used to score each candidate answer.
- Hypothesis Filtering module 522 is used to filter the candidate answers based on the scores provided in Processing module 524 .
- Candidate answers with low scores are omitted from supporting passage retrieval at 40 A; i.e., these candidate answers are considered to be not good enough to be worth the computational cost of searching for supporting evidence.
- the threshold used to identify low-scoring answers may be obtained by optimizing over a given data set, e.g., performing a parameter sweep to select for an optimal tradeoff between computational cost and final answer quality metrics. The remaining candidate answers are considered to be good enough to merit further investigation.
- a pathway 536 is provided in which a candidate answer is sent from the Hypothesis Filtering module 522 to the Supporting Passage Retrieval Process 40 A.
- This pathway 536 is used only for candidate answers which have received a sufficiently high score from Hypothesis Filtering module 522
- a pathway 540 is also provided in which a candidate answer is sent from the Hypothesis Filtering module 522 to the Post-Filter Context Independent Candidate Answer Processing module 526 .
- This pathway 540 is also used only for candidate answers which have received a sufficiently high score from the Hypothesis Filtering module.
- a pathway 542 is also provided in which candidate answers are sent from the Hypothesis Filtering Module 522 to the Final Merging/Ranking process 570 .
- this pathway 542 is used only for candidate answers which have received a low score form the Hypotheses Filtering module 522 . Candidates along this path are still included in the final answer ranking, but do not benefit from the supporting evidence and analysis that occurs in the post-filter answer scoring at 40 A and 40 B.
- the Evidence Gathering module 50 (shown in FIGS. 1 and 3 ) that implements (parallel processing) and supports passage retrieval and answer scoring according to embodiments of the invention is now described in greater detail with respect to FIG. 5 .
- passage retrieval is used in candidate answer generation wherein using keywords from the question, passages are found from unstructured corpora. Then candidate answers are extracted from those passages.
- Supporting Passage Retrieval (SPR) 40 A operates after candidate answer generation. For each resulting candidate passage, the passage content are traversed to find/look for those passages having candidate answers in addition to question terms. It is understood that better passages can be found if it is known what candidate answer is being looked for. For each candidate answer passed to SPR 40 A, the sources are traversed to find those passages having candidate answers in addition to question terms (i.e., another search is conducted against the original primary sources (databases) or the Candidate KB). In another embodiment, the search can be conducted against cached search results (past passages). It is understood that the best results are obtained if the search is repeated with candidate answers included together with the question terms.
- SPR Supporting Passage Retrieval
- Supporting Passages are then scored by multiple Scorers by conducting one or more of the following: Simple Term Match Score; textual Alignment; and a deeper analysis.
- Simple Term Match Score implements executable instructions for counting the number of terms that match
- Textual Alignment implements executable instructions for determining if words appear in the same or similar order with a similar distance between them so they are not separated much (aligned). This is advantageous to find a quotation. To find quotes, for example, an alignment would be performed to get the best result.
- Deeper analysis implements executable instructions for determining the meaning of the passages/question (i.e., lexical and/or semantic relations). Each of these analyses produces a score.
- stopword removal that is removal from the query of the most frequent words such as “a”, “an”, “the”, “is/was/be . . . ”, “become/became . . . ” . . .
- the query becomes: ‘Republican first sitting senator ever host aturday Night Live?2002’.
- the query is sent to an Internet search engine, e.g., such as provided by MSN, and the top 20 result documents are read.
- An Internet search engine e.g., such as provided by MSN
- the following depicts example passage extraction results (candidate answers) for the example question search results for ‘Republican first sitting senator ever host aturday Night Live?2002’.
- passages are identified that include each candidate answer (i.e., John McCain or Al Gore), along with as many question keywords as possible shown italicized.
- Passage Score # of query terms in passage/total # of query terms
- the answer scores for each candidate answer would be included in the CAS.
- supporting passages are retrieved. Functionality is initiated after the CAS split and receiving filtered candidate answers from Hypothesis Filter 522 .
- Supporting passage records created by Supporting Passage Retrieval are split by Supporting Passage Splitter 548 ; and since there may be many of them, the splitter routes the new CASes (with all information that was computed previously: context, query, candidate answer, supporting passage) to Answer Scoring 40 B.
- the candidate scoring performed by candidate scoring module 40 B can be subdivided into two classes: context independent scoring 43 (where the answer can be scored independently of the passage), and context dependent scoring 47 (where the answer score depends on the passage content). For example, as mentioned above, if the candidate answer is obtained from the document title, the score will not be dependent on the content of the passage, and is context independent.
- other types of candidate answer scoring based on text alignment module 405 , FIG. 4
- grammatical relations module 410 , FIG.
- lexical and semantic relations module 402 , FIG. 4
- search results must be processed (in the Search Result Processing module in SPR block 40 A) prior to Context Dependent Candidate Answer processing in 47 .
- the results of an answer scorer are saved in the CAS.
- all of the candidate answer features are aggregated and merged, and the final candidate answer scoring function is applied (as described above with respect to the example scores provided in Table 1. Since a given candidate answer may appear in multiple passages, the Final Merge/Rank annotator must collect results across CASes, normalize and merge candidate answers, merge feature scores produced by the same answer scorer across multiple instances of the candidate answer, and aggregate the results.
- the normalized, merged, and aggregated results are input to the scoring function to produce a final score for the candidate answer.
- the final scoring results are saved as an answer and//or delivered to a user.
- Final merging and ranking is incremental, i.e., the machine provides the best answer so far as the computation on different nodes completes. Once all nodes complete, the final (top) answer(s) is delivered. Thus, in one embodiment, the final AnswerList and Answers are added to the original Question view, and the question answering process is complete.
- a person skilled in the art would be able to implement a further extension to the system of the invention to employ modes of multimodal communication (using U.S. Pat. No. 7,136,909) involving multiple modalities of text, audio, video, gesture, tactile input and output etc.
- modes of multimodal communication using U.S. Pat. No. 7,136,909
- examples of such interaction include a cell phone user who is asking a question using voice and is receiving an answer in a combination of other modalities (voice, text and image), or an interaction with a video game.
- the data model and processing models described herein are designed to enable parallel processing, and to admit a “streaming” model of computation, where results become available incrementally, before all processing is complete.
- This streaming model may be advantageous if the analytics are able to identify and process the most likely candidates first, and continue to improve scoring estimates with more processing time.
- the above-described modules of FIGS. 1-5 can be represented as functional components in UIMA and may be embodied as a combination of hardware and software for developing applications that integrate search and analytics over a combination of structured and unstructured information.
- the software program that employs UIMA components to implement end-user capability is generally referred to as the application, the application program, or the software application.
- the UIMA high-level architecture defines the roles, interfaces and communications of large-grained components that cooperate to implement UIM applications. These include components capable of analyzing unstructured source artifacts, such as documents containing textual data and/or image data, integrating and accessing structured sources and storing, indexing and searching for artifacts based on discovered semantic content.
- a non-limiting embodiment of the UIMA high-level architecture includes a Semantic Search Engine, a Document Store, at least one Text Analysis Engine (TAE), at least one Structured Knowledge Source Adapter, a Collection Processing Manager, at least one Collection Analysis Engine, all interfacing with application logic.
- TAE Text Analysis Engine
- the UIMA operates to access both structured information and unstructured information to generate candidate answers and an answer in the manner as discussed herein.
- the unstructured information may be considered to be a collection of documents, and can be in the form of text, graphics, static and dynamic images, audio and various combinations thereof.
- FIG. 8 Aspects of the UIMA are further shown in FIG. 8 , where there is illustrated an Analysis Engine (AE) 600 that can be a component part of the Text Analysis Engine. Included in the AE 600 is a Common Analysis System (CAS) 610 , an annotator 620 and a controller 630 .
- AE 600 Analysis Engine 600
- CAS Common Analysis System
- a second embodiment of a TAE includes an aggregate Analysis Engine composed of two or more component analysis engines as well as the CAS, and implements the same external interface as the AE 600 .
- the Common Analysis System (CAS) 610 is provided as the common facility that all Annotators 620 use for accessing and modifying analysis structures.
- the CAS 610 enables coordination between annotators 620 and facilitates annotator 620 reuse within different applications and different types of architectures (e.g. loosely vs. tightly coupled).
- the CAS 610 can be considered to constrain operation of the various annotators.
- the CAS 610 principally provides for data modeling, data creation and data retrieval functions.
- Data modeling preferably defines a tree hierarchy of types, as shown in the example Table 2 provided below.
- the types have attributes or properties referred to as features.
- predefined built-in
- the data model is defined in the annotator descriptor, and shared with other annotators.
- some ypes?that are considered extended from prior art unstructured information management applications to accommodate question answering in embodiments of the invention include:
- CAS 610 data structures may be referred to as “feature structures.”
- feature structures To create a feature structure, the type must be specified (see TABLE 2). Annotations (and—feature structures) are stored in indexes.
- the CAS 610 may be considered to be a collection of methods (implemented as a class, for example, in Java or C++) that implements an expressive object-based data structure as an abstract data type.
- the CAS 610 design is largely based on a TAE 130 Feature-Property Structure that provides user-defined objects, properties and values for flexibility, a static type hierarchy for efficiency, and methods to access the stored data through the use of one or more iterators.
- the abstract data model implemented through the CAS 610 provides the UIMA 100 with, among other features: platform independence (i.e., the type system is defined declaratively, independently of a programming language); performance advantages (e.g., when coupling annotators 620 written in different programming languages through a common data model); flow composition by input/output specifications for annotators 620 (that includes declarative specifications that allow type checking and error detection, as well as support for annotators (TAE) as services models); and support for third generation searching procedures through semantic indexing, search and retrieval (i.e. semantic types are declarative, not key-word based).
- platform independence i.e., the type system is defined declaratively, independently of a programming language
- performance advantages e.g., when coupling annotators 620 written in different programming languages through a common data model
- flow composition by input/output specifications for annotators 620 that includes declarative specifications that allow type checking and error detection, as well as support for annotators (TAE) as services models
- TEE support for
- the CAS 610 provides the annotator 620 with a facility for efficiently building and searching an analysis structure.
- the analysis structure is a data structure that is mainly composed of meta-data descriptive of sub-sequences of the text of the original document.
- An exemplary type of meta-data in an analysis structure is the annotation.
- An annotation is an object, with its own properties, that is used to annotate a sequence of text.
- annotations may label sequences of text in terms of their role in the document's structure (e.g., word, sentence, paragraph etc), or to describe them in terms of their grammatical role (e.g., noun, noun phrase, verb, adjective etc.).
- annotations There is essentially no limit on the number of, or application of, annotations. Other examples include annotating segments of text to identify them as proper names, locations, military targets, times, events, equipment, conditions, temporal conditions, relations, biological relations, family relations or other items of significance or interest.
- an Annotator's 620 function is to analyze text, as well as an existing analysis structure, to discover new instances of the set of annotations that it is designed to recognize, and then to add these annotations to the analysis structure for input to further processing by other annotators 220 .
- the CAS 610 of FIG. 6 may store the original document text, as well as related documents that may be produced by the annotators 620 (e.g., translations and/or summaries of the original document).
- the CAS 610 includes extensions that facilitate the export of different aspects of the analysis structure (for example, a set of annotations) in an established format, such as XML.
- the CAS 610 is that portion of the TAE that defines and stores annotations of text.
- the CAS API is used both by the application and the annotators 620 to create and access annotations.
- the CAS API includes, for example, three distinct interfaces.
- a Type system controls creation of new types and provides information about the relationship between types (inheritance) and types and features.
- type definitions is provided in TABLE 1.
- a Structure Access Interface handles the creation of new structures and the accessing and setting of values.
- a Structure Query Interface deals with the retrieval of existing structures.
- the Type system provides a classification of entities known to the system, similar to a class hierarchy in object-oriented programming. Types correspond to classes, and features correspond to member variables.
- the Type system interface provides the following functionality: add a new type by providing a name for the new type and specifying the place in the hierarchy where it should be attached; add a new feature by providing a name for the new feature and giving the type that the feature should be attached to, as well as the value type; and query existing types and features, and the relations among them, such as “which type(s) inherit from this type”.
- the Type system provides a small number of built-in types.
- the basic types are int, float and string. In a Java implementation, these correspond to the Java int, float and string types, respectively. Arrays of annotations and basic data types are also supported.
- the built-in types have special API support in the Structure Access Interface.
- the Structure Access Interface permits the creation of new structures, as well as accessing and setting the values of existing structures. In an embodiment, this provides for creating a new structure of a given type, getting and setting the value of a feature on a given structure, and accessing methods for built-in types. Feature definitions are provided for domains, each feature having a range.
- modules of FIGS. 1-5 can be represented as functional components in GATE (General Architecture for Text Engineering) (see: http://gate.ac.uk/releases/gate-2.0alpha2-build484/doc/userguide.html).
- GATE employs components which are reusable software chunks with well-defined interfaces that are conceptually separate from GATE itself. All component sets are user-extensible and together are called CREOLE—a Collection of REusable Objects for Language Engineering.
- the GATE framework is a backplane into which plug CREOLE components. The user gives the system a list of URLs to search when it starts up, and components at those locations are loaded by the system.
- GATE components are one of three types of specialized Java Beans: 1) Resource; 2) Processing Resource; 3) Language Resource; and 4) Visual Resource.
- Resource is a top-level interface, which describes all components. What all components share in common is that they can be loaded at runtime, and that the set of components is extendable by clients. They have Features, which are represented externally to the system as “meta-data” in a format such as RDF, plain XML, or Java properties. Resources may all be Java beans in one embodiment.
- ProcessingResource is a resource that is runnable, may be invoked remotely (via RMI), and lives in class files.
- Language Resource is a resource that consists of data, accessed via a Java abstraction layer. They live in relational databases.
- VisualResource is a visual Java bean, component of GUIs, including of the main GATE gui. Like PRs these components live in .class or .jar files.
- a PR is a Resource that implements the Java Runnable interface.
- the GATE Visualisation Model implements resources whose task is to display and edit other resources are modelled as Visual Resources.
- the Corpus Model in GATE is a Java Set whose members are documents.
- Both Corpora and Documents are types of Language Resources (LR) with all LRs having a Feature Map (a Java Map) associated with them that stores attribute/value information about the resource.
- FeatureMaps are also used to associate arbitrary information with ranges of documents (e.g. pieces of text) via an annotation model.
- Documents have a DocumentContent which is a text at present (future versions may add support for audiovisual content) and one or more AnnotationSets which are Java Sets.
- Embodiments of the invention can take the form of an entirely hardware embodiment, an entirely software embodiment or an embodiment containing both hardware and software elements.
- the invention is implemented in software, which includes but is not limited, to firmware, resident software, microcode, etc.
- the invention can take the form of a computer program product accessible from a computer-usable or computer-readable medium providing program code for use by or in connection with a computer or any instruction execution system.
- a computer usable or computer readable medium can be any apparatus that can contain, store, communicate, propagate, or transport the program for use by or in connection with the instruction execution system, apparatus or device.
- the medium can be an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system (or apparatus or device) or a propagation medium.
- Examples of a computer-readable medium include a semiconductor or solid state memory, magnetic tape, a removable computer diskette, a random access memory (RAM), a read only memory (ROM), a rigid magnetic disk and an optical disk.
- Current examples of optical disks include compact disk read only memory (CD-ROM), compact disk read/write (CD-R/W), and DVD.
- the system and method of the present disclosure may be implemented and run on a general-purpose computer or computer system.
- the computer system may be any type of known or will be known systems and may typically include a processor, memory device, a storage device, input/output devices, internal buses, and/or a communications interface for communicating with other computer systems in conjunction with communication hardware and software, etc.
- the terms “computer system” and “computer network” as may be used in the present application may include a variety of combinations of fixed and/or portable computer hardware, software, peripherals, and storage devices.
- the computer system may include a plurality of individual components that are networked or otherwise linked to perform collaboratively, or may include one or more stand-alone components.
- the hardware and software components of the computer system of the present application may include and may be included within fixed and portable devices such as desktop, laptop, and server.
- a module may be a component of a device, software, program, or system that implements some “functionality”, which can be embodied as software, hardware, firmware, electronic circuitry, or etc.
- the term “user” refers to a person or persons interacting with the system
- the term “user query” refers to a query posed by the user.
- the “user” refers to the computer system generating a query by mechanical means
- the term “user query” refers to such a mechanically generated query.
- the “user query” can be a natural language expression, a formal language expression, or a combination of natural language and formal language expressions.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Human Computer Interaction (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
-
- 1) Run context independent scorers on the candidate answers (since those scorers do not require supporting passages).
- 2) Use a scoring function (e.g., a logistic regression model) to score each candidate answer.
- 3) Candidate answers with very low scores are omitted from supporting passage retrieval; i.e., they are considered to be not good enough to be worth the computational cost of searching for supporting evidence. The threshold used to identify low-scoring answers may be obtained by optimizing over a held-out data set, e.g., performing a parameter sweep to select for an optimal tradeoff between computational cost and final answer quality metrics.
- 4) The remaining candidate answers are considered to be good enough to merit further investigation.
| TABLE 1 | ||||||
| Candidate | Type | Align | Rank | Score | ||
| Milk | 1 | 0.2 | 3 | 0.46 | ||
| Muscovado | 0 | 0.6 | 1 | 0.48 | ||
| Molasses | 1 | 0.5 | 2 | 0.8 | ||
-
- 1. A CAS represents a single question however, it is not so limited, i.e., includes the question of some prior focus (category, prior question or answer, or question meta-data some element of the context is also provided);
- 2. The question is the subject of analysis in the initial CAS view;
- 3. Processing is divided into several phases, where each phase may generate multiple, new CASes with new subjects of analysis and corresponding views, but the original question view is carried in every CAS. It is understood that variations are possible.
Passage Score=# of query terms in passage/total # of query terms
Candidate: John McCain
Document: http://doney.net/aroundaz/celebrity/mccain_john.htm Passage: Representative from Arizona 1st District (1983-1987), POW (1967-1972), Navy pilot, first sitting Senator to host Saturday Night Live (2002) Born in the Panama Canal Zone, John McCain shares the headstrong, blunt, maverick traits of his father and grandfather, who were the first father and son four star Admirals in the U.S.
Passage Score: 8/11=0.73
Candidate: Al Gore
Document: http://www.imdb.com/title/tt0072562/news Passage: 17 Dec. 2002
(StudioBriefing) No longer a candidate for the presidency in 2004, Al Gore may have a whole new career cut out for him as the host of a late-night comedy show, judging by the ratings for the December 14 edition of NBC's Saturday Night Live.
Passage Score: 5/11=0.45
AnswerScore=P 0 +nP 1 +n 2 P 2 +n 3 P 3+ . . . 1)
where, Pi is the ith highest passage score, and “n” is a constant<1 (e.g., 0.1).
| TABLE 2 | |
| TYPE (or feature) | TYPE's PARENT (or feature type) |
| Query Record | Top |
| Query | Query Record |
| Query Context | Query Record |
| Candidate Answer Record | Annotation |
| Candidate Answer | Candidate Answer Record |
| Feature: CandidateAnswerScore | Float |
| Supporting Passage Record | Candidate Answer Record |
| Feature: SupportingPassageScore | Float |
Claims (17)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/267,688 US11409751B2 (en) | 2010-09-28 | 2019-02-05 | Providing answers to questions using hypothesis pruning |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US38715710P | 2010-09-28 | 2010-09-28 | |
| US13/240,140 US9317586B2 (en) | 2010-09-28 | 2011-09-22 | Providing answers to questions using hypothesis pruning |
| US15/131,650 US10216804B2 (en) | 2010-09-28 | 2016-04-18 | Providing answers to questions using hypothesis pruning |
| US16/267,688 US11409751B2 (en) | 2010-09-28 | 2019-02-05 | Providing answers to questions using hypothesis pruning |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/131,650 Continuation US10216804B2 (en) | 2010-09-28 | 2016-04-18 | Providing answers to questions using hypothesis pruning |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20190171646A1 US20190171646A1 (en) | 2019-06-06 |
| US11409751B2 true US11409751B2 (en) | 2022-08-09 |
Family
ID=45871688
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/240,140 Expired - Fee Related US9317586B2 (en) | 2010-09-28 | 2011-09-22 | Providing answers to questions using hypothesis pruning |
| US13/613,999 Expired - Fee Related US9323831B2 (en) | 2010-09-28 | 2012-09-13 | Providing answers to questions using hypothesis pruning |
| US15/131,650 Active 2032-03-27 US10216804B2 (en) | 2010-09-28 | 2016-04-18 | Providing answers to questions using hypothesis pruning |
| US16/267,688 Active 2033-11-29 US11409751B2 (en) | 2010-09-28 | 2019-02-05 | Providing answers to questions using hypothesis pruning |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/240,140 Expired - Fee Related US9317586B2 (en) | 2010-09-28 | 2011-09-22 | Providing answers to questions using hypothesis pruning |
| US13/613,999 Expired - Fee Related US9323831B2 (en) | 2010-09-28 | 2012-09-13 | Providing answers to questions using hypothesis pruning |
| US15/131,650 Active 2032-03-27 US10216804B2 (en) | 2010-09-28 | 2016-04-18 | Providing answers to questions using hypothesis pruning |
Country Status (4)
| Country | Link |
|---|---|
| US (4) | US9317586B2 (en) |
| EP (1) | EP2622428A4 (en) |
| CN (1) | CN103229120A (en) |
| WO (1) | WO2012047532A1 (en) |
Families Citing this family (103)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120078062A1 (en) | 2010-09-24 | 2012-03-29 | International Business Machines Corporation | Decision-support application and system for medical differential-diagnosis and treatment using a question-answering system |
| US8862543B2 (en) * | 2011-06-13 | 2014-10-14 | Business Objects Software Limited | Synchronizing primary and secondary repositories |
| US9117194B2 (en) | 2011-12-06 | 2015-08-25 | Nuance Communications, Inc. | Method and apparatus for operating a frequently asked questions (FAQ)-based system |
| US9229974B1 (en) | 2012-06-01 | 2016-01-05 | Google Inc. | Classifying queries |
| KR101375282B1 (en) * | 2012-09-20 | 2014-03-17 | 한국전력공사 | System and method for electric power system data abbreviation |
| US9411803B2 (en) * | 2012-09-28 | 2016-08-09 | Hewlett Packard Enterprise Development Lp | Responding to natural language queries |
| US9443005B2 (en) * | 2012-12-14 | 2016-09-13 | Instaknow.Com, Inc. | Systems and methods for natural language processing |
| US9015097B2 (en) * | 2012-12-19 | 2015-04-21 | Nuance Communications, Inc. | System and method for learning answers to frequently asked questions from a semi-structured data source |
| US20140207712A1 (en) * | 2013-01-22 | 2014-07-24 | Hewlett-Packard Development Company, L.P. | Classifying Based on Extracted Information |
| US9258597B1 (en) | 2013-03-13 | 2016-02-09 | Google Inc. | System and method for obtaining information relating to video images |
| US9251474B2 (en) | 2013-03-13 | 2016-02-02 | International Business Machines Corporation | Reward based ranker array for question answer system |
| US9247309B2 (en) | 2013-03-14 | 2016-01-26 | Google Inc. | Methods, systems, and media for presenting mobile content corresponding to media content |
| US9705728B2 (en) | 2013-03-15 | 2017-07-11 | Google Inc. | Methods, systems, and media for media transmission and management |
| US9064001B2 (en) | 2013-03-15 | 2015-06-23 | Nuance Communications, Inc. | Method and apparatus for a frequently-asked questions portal workflow |
| US9613317B2 (en) | 2013-03-29 | 2017-04-04 | International Business Machines Corporation | Justifying passage machine learning for question and answer systems |
| US9621601B2 (en) * | 2013-03-29 | 2017-04-11 | International Business Machines Corporation | User collaboration for answer generation in question and answer system |
| US9146987B2 (en) | 2013-06-04 | 2015-09-29 | International Business Machines Corporation | Clustering based question set generation for training and testing of a question and answer system |
| US9230009B2 (en) | 2013-06-04 | 2016-01-05 | International Business Machines Corporation | Routing of questions to appropriately trained question and answer system pipelines using clustering |
| US9275115B2 (en) * | 2013-07-16 | 2016-03-01 | International Business Machines Corporation | Correlating corpus/corpora value from answered questions |
| CN103559283A (en) * | 2013-11-07 | 2014-02-05 | 百度在线网络技术(北京)有限公司 | Information providing method, system, server and search system |
| US10162813B2 (en) | 2013-11-21 | 2018-12-25 | Microsoft Technology Licensing, Llc | Dialogue evaluation via multiple hypothesis ranking |
| US20150149450A1 (en) * | 2013-11-27 | 2015-05-28 | International Business Machines Corporation | Determining problem resolutions within a networked computing environment |
| CN103699574B (en) * | 2013-11-28 | 2017-01-11 | 科大讯飞股份有限公司 | Retrieval optimization method and system for complex retrieval formula |
| US9348900B2 (en) | 2013-12-11 | 2016-05-24 | International Business Machines Corporation | Generating an answer from multiple pipelines using clustering |
| US10002191B2 (en) | 2013-12-31 | 2018-06-19 | Google Llc | Methods, systems, and media for generating search results based on contextual information |
| US9456237B2 (en) | 2013-12-31 | 2016-09-27 | Google Inc. | Methods, systems, and media for presenting supplemental information corresponding to on-demand media content |
| US10210156B2 (en) * | 2014-01-10 | 2019-02-19 | International Business Machines Corporation | Seed selection in corpora compaction for natural language processing |
| US9959315B1 (en) * | 2014-01-31 | 2018-05-01 | Google Llc | Context scoring adjustments for answer passages |
| US10467302B2 (en) | 2014-02-11 | 2019-11-05 | International Business Machines Corporation | Candidate answers for speculative questions in a deep question answering system |
| US9633137B2 (en) | 2014-04-24 | 2017-04-25 | International Business Machines Corporation | Managing questioning in a question and answer system |
| US9607035B2 (en) | 2014-05-21 | 2017-03-28 | International Business Machines Corporation | Extensible validation framework for question and answer systems |
| US9754207B2 (en) | 2014-07-28 | 2017-09-05 | International Business Machines Corporation | Corpus quality analysis |
| US9501525B2 (en) * | 2014-11-05 | 2016-11-22 | International Business Machines Corporation | Answer sequence evaluation |
| US20160133148A1 (en) * | 2014-11-06 | 2016-05-12 | PrepFlash LLC | Intelligent content analysis and creation |
| US10331673B2 (en) | 2014-11-24 | 2019-06-25 | International Business Machines Corporation | Applying level of permanence to statements to influence confidence ranking |
| US10102289B2 (en) * | 2014-12-02 | 2018-10-16 | International Business Machines Corporation | Ingesting forum content |
| US10180988B2 (en) | 2014-12-02 | 2019-01-15 | International Business Machines Corporation | Persona-based conversation |
| US9846738B2 (en) * | 2014-12-05 | 2017-12-19 | International Business Machines Corporation | Dynamic filter optimization in deep question answering systems |
| US10176228B2 (en) * | 2014-12-10 | 2019-01-08 | International Business Machines Corporation | Identification and evaluation of lexical answer type conditions in a question to generate correct answers |
| US9811515B2 (en) | 2014-12-11 | 2017-11-07 | International Business Machines Corporation | Annotating posts in a forum thread with improved data |
| US10303798B2 (en) * | 2014-12-18 | 2019-05-28 | Nuance Communications, Inc. | Question answering from structured and unstructured data sources |
| US10108906B2 (en) * | 2014-12-19 | 2018-10-23 | International Business Machines Corporation | Avoiding supporting evidence processing when evidence scoring does not affect final ranking of a candidate answer |
| US9652717B2 (en) * | 2014-12-19 | 2017-05-16 | International Business Machines Corporation | Avoidance of supporting evidence processing based on key attribute predictors |
| US9633019B2 (en) * | 2015-01-05 | 2017-04-25 | International Business Machines Corporation | Augmenting an information request |
| US10366107B2 (en) | 2015-02-06 | 2019-07-30 | International Business Machines Corporation | Categorizing questions in a question answering system |
| US10795921B2 (en) * | 2015-03-27 | 2020-10-06 | International Business Machines Corporation | Determining answers to questions using a hierarchy of question and answer pairs |
| US9460713B1 (en) * | 2015-03-30 | 2016-10-04 | Google Inc. | Language model biasing modulation |
| US9684876B2 (en) | 2015-03-30 | 2017-06-20 | International Business Machines Corporation | Question answering system-based generation of distractors using machine learning |
| US10204104B2 (en) | 2015-04-14 | 2019-02-12 | Google Llc | Methods, systems, and media for processing queries relating to presented media content |
| US10586156B2 (en) | 2015-06-25 | 2020-03-10 | International Business Machines Corporation | Knowledge canvassing using a knowledge graph and a question and answer system |
| US10223440B2 (en) * | 2015-06-29 | 2019-03-05 | International Business Machines Corporation | Question and answer system emulating people and clusters of blended people |
| US10339916B2 (en) | 2015-08-31 | 2019-07-02 | Microsoft Technology Licensing, Llc | Generation and application of universal hypothesis ranking model |
| US9478145B1 (en) * | 2015-11-24 | 2016-10-25 | International Business Machines Corporation | Unreasonable answer filter |
| KR102558437B1 (en) | 2015-11-27 | 2023-07-24 | 삼성전자주식회사 | Method For Processing of Question and answer and electronic device supporting the same |
| US9495648B1 (en) | 2015-12-11 | 2016-11-15 | International Business Machines Corporation | Training a similar passage cognitive system using ground truth from a question answering cognitive system |
| US9720981B1 (en) * | 2016-02-25 | 2017-08-01 | International Business Machines Corporation | Multiple instance machine learning for question answering systems |
| CN109219811B (en) | 2016-05-23 | 2022-03-29 | 微软技术许可有限责任公司 | Related paragraph retrieval system |
| US10607153B2 (en) | 2016-06-28 | 2020-03-31 | International Business Machines Corporation | LAT based answer generation using anchor entities and proximity |
| AU2016412564A1 (en) * | 2016-06-29 | 2019-01-24 | Razer (Asia-Pacific) Pte. Ltd. | Data providing methods, data providing systems, and computer-readable media |
| CN107665188B (en) * | 2016-07-27 | 2021-01-29 | 科大讯飞股份有限公司 | Semantic understanding method and device |
| US10133724B2 (en) * | 2016-08-22 | 2018-11-20 | International Business Machines Corporation | Syntactic classification of natural language sentences with respect to a targeted element |
| US10394950B2 (en) | 2016-08-22 | 2019-08-27 | International Business Machines Corporation | Generation of a grammatically diverse test set for deep question answering systems |
| US11087087B1 (en) * | 2017-02-15 | 2021-08-10 | Robert Mayer | Comparative expression processing |
| US10860628B2 (en) * | 2017-02-16 | 2020-12-08 | Google Llc | Streaming real-time dialog management |
| US20180232443A1 (en) * | 2017-02-16 | 2018-08-16 | Globality, Inc. | Intelligent matching system with ontology-aided relation extraction |
| CN108509463B (en) | 2017-02-28 | 2022-03-29 | 华为技术有限公司 | Question response method and device |
| US11729120B2 (en) | 2017-03-16 | 2023-08-15 | Microsoft Technology Licensing, Llc | Generating responses in automated chatting |
| US10289615B2 (en) * | 2017-05-15 | 2019-05-14 | OpenGov, Inc. | Natural language query resolution for high dimensionality data |
| US10769138B2 (en) | 2017-06-13 | 2020-09-08 | International Business Machines Corporation | Processing context-based inquiries for knowledge retrieval |
| US11093709B2 (en) | 2017-08-10 | 2021-08-17 | International Business Machine Corporation | Confidence models based on error-to-correction mapping |
| CN107491534B (en) * | 2017-08-22 | 2020-11-20 | 北京百度网讯科技有限公司 | Information processing method and device |
| CN110020007A (en) * | 2017-09-15 | 2019-07-16 | 上海挖数互联网科技有限公司 | Robot interactive control method and device, storage medium, server |
| CN107580062A (en) * | 2017-09-15 | 2018-01-12 | 吴兰岸 | A kind of long-distance management system of educational robot |
| CN107844531B (en) * | 2017-10-17 | 2020-05-22 | 东软集团股份有限公司 | Answer output method and device and computer equipment |
| CN107832439B (en) | 2017-11-16 | 2019-03-08 | 百度在线网络技术(北京)有限公司 | Method, system and the terminal device of more wheel state trackings |
| US10915560B2 (en) | 2017-11-30 | 2021-02-09 | International Business Machines Corporation | Ranking passages by merging features from factoid answers |
| CN110019719B (en) * | 2017-12-15 | 2023-04-25 | 微软技术许可有限责任公司 | Assertion-based question and answer |
| US10810215B2 (en) * | 2017-12-15 | 2020-10-20 | International Business Machines Corporation | Supporting evidence retrieval for complex answers |
| CN108170749B (en) * | 2017-12-21 | 2021-06-11 | 北京百度网讯科技有限公司 | Dialog method, device and computer readable medium based on artificial intelligence |
| US11157564B2 (en) * | 2018-03-02 | 2021-10-26 | Thoughtspot, Inc. | Natural language question answering systems |
| US10997221B2 (en) * | 2018-04-07 | 2021-05-04 | Microsoft Technology Licensing, Llc | Intelligent question answering using machine reading comprehension |
| US11307880B2 (en) | 2018-04-20 | 2022-04-19 | Meta Platforms, Inc. | Assisting users with personalized and contextual communication content |
| US11886473B2 (en) | 2018-04-20 | 2024-01-30 | Meta Platforms, Inc. | Intent identification for agent matching by assistant systems |
| US10978056B1 (en) * | 2018-04-20 | 2021-04-13 | Facebook, Inc. | Grammaticality classification for natural language generation in assistant systems |
| US11715042B1 (en) | 2018-04-20 | 2023-08-01 | Meta Platforms Technologies, Llc | Interpretability of deep reinforcement learning models in assistant systems |
| US11010179B2 (en) | 2018-04-20 | 2021-05-18 | Facebook, Inc. | Aggregating semantic information for improved understanding of users |
| US11676220B2 (en) | 2018-04-20 | 2023-06-13 | Meta Platforms, Inc. | Processing multimodal user input for assistant systems |
| US11989229B2 (en) | 2018-05-03 | 2024-05-21 | Google Llc | Coordination of overlapping processing of audio queries |
| US11016985B2 (en) * | 2018-05-22 | 2021-05-25 | International Business Machines Corporation | Providing relevant evidence or mentions for a query |
| CN108960319B (en) * | 2018-06-29 | 2019-12-03 | 哈尔滨工业大学 | It is a kind of to read the candidate answers screening technique understood in modeling towards global machine |
| CN110765338B (en) * | 2018-07-26 | 2024-11-08 | 北京搜狗科技发展有限公司 | A data processing method, a data processing device and a data processing device |
| US11822588B2 (en) | 2018-10-24 | 2023-11-21 | International Business Machines Corporation | Supporting passage ranking in question answering (QA) system |
| US11106717B2 (en) * | 2018-11-19 | 2021-08-31 | International Business Machines Corporation | Automatic identification and clustering of patterns |
| US11043214B1 (en) * | 2018-11-29 | 2021-06-22 | Amazon Technologies, Inc. | Speech recognition using dialog history |
| US20200401878A1 (en) | 2019-06-19 | 2020-12-24 | International Business Machines Corporation | Collaborative real-time solution efficacy |
| US11442932B2 (en) | 2019-07-16 | 2022-09-13 | Thoughtspot, Inc. | Mapping natural language to queries using a query grammar |
| WO2021064482A1 (en) * | 2019-09-30 | 2021-04-08 | International Business Machines Corporation | Machine learning module for a dialog system |
| CN110837550B (en) * | 2019-11-11 | 2023-01-17 | 中山大学 | Question answering method, device, electronic equipment and storage medium based on knowledge graph |
| CN111949756A (en) * | 2020-07-16 | 2020-11-17 | 新疆中顺鑫和供应链管理股份有限公司 | Hazardous chemical substance retrieval method, hazardous chemical substance retrieval device, electronic equipment and medium |
| US11416686B2 (en) * | 2020-08-05 | 2022-08-16 | International Business Machines Corporation | Natural language processing based on user context |
| US11880661B2 (en) | 2021-03-26 | 2024-01-23 | International Business Machines Corporation | Unsupervised dynamic confidence thresholding for answering questions |
| CN115455160B (en) * | 2022-09-02 | 2024-08-06 | 腾讯科技(深圳)有限公司 | Multi-document reading and understanding method, device, equipment and storage medium |
| US12253988B1 (en) * | 2023-10-17 | 2025-03-18 | Originality.ai Inc. | Text analysis and verification methods and systems |
Citations (92)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3559995A (en) | 1968-04-29 | 1971-02-02 | Psychomantic Game Co | Question answering gameboard and spinner |
| US4594686A (en) | 1979-08-30 | 1986-06-10 | Sharp Kabushiki Kaisha | Language interpreter for inflecting words from their uninflected forms |
| US4599691A (en) | 1982-05-20 | 1986-07-08 | Kokusai Denshin Denwa Co., Ltd. | Tree transformation system in machine translation system |
| US4829423A (en) | 1983-01-28 | 1989-05-09 | Texas Instruments Incorporated | Menu-based natural language understanding system |
| US4921427A (en) | 1989-08-21 | 1990-05-01 | Dunn Jeffery W | Educational device |
| US5237502A (en) | 1990-09-04 | 1993-08-17 | International Business Machines Corporation | Method and apparatus for paraphrasing information contained in logical forms |
| US5374894A (en) | 1992-08-19 | 1994-12-20 | Hyundai Electronics America | Transition detection circuit |
| US5414797A (en) | 1991-05-16 | 1995-05-09 | International Business Machines Corp. | Clustering fuzzy expected value system |
| US5513116A (en) | 1988-12-08 | 1996-04-30 | Hallmark Cards Incorporated | Computer controlled machine for vending personalized products or the like |
| US5519608A (en) * | 1993-06-24 | 1996-05-21 | Xerox Corporation | Method for extracting from a text corpus answers to questions stated in natural language by using linguistic analysis and hypothesis generation |
| US5546316A (en) | 1990-10-22 | 1996-08-13 | Hallmark Cards, Incorporated | Computer controlled system for vending personalized products |
| US5550746A (en) | 1994-12-05 | 1996-08-27 | American Greetings Corporation | Method and apparatus for storing and selectively retrieving product data by correlating customer selection criteria with optimum product designs based on embedded expert judgments |
| US5559714A (en) | 1990-10-22 | 1996-09-24 | Hallmark Cards, Incorporated | Method and apparatus for display sequencing personalized social occasion products |
| US5634051A (en) | 1993-10-28 | 1997-05-27 | Teltech Resource Network Corporation | Information management system |
| US5794050A (en) | 1995-01-04 | 1998-08-11 | Intelligent Text Processing, Inc. | Natural language understanding system |
| US20010032211A1 (en) | 2000-04-13 | 2001-10-18 | Hiroshi Kuzumaki | Question answering system and storage medium |
| US20020169595A1 (en) | 2001-03-30 | 2002-11-14 | Yevgeny Agichtein | Method for retrieving answers from an information retrieval system |
| US6487545B1 (en) | 1995-05-31 | 2002-11-26 | Oracle Corporation | Methods and apparatus for classifying terminology utilizing a knowledge catalog |
| US20030033287A1 (en) | 2001-08-13 | 2003-02-13 | Xerox Corporation | Meta-document management system with user definable personalities |
| US20030033288A1 (en) | 2001-08-13 | 2003-02-13 | Xerox Corporation | Document-centric system with auto-completion and auto-correction |
| US6618772B1 (en) | 1996-11-15 | 2003-09-09 | Kim Y. Kao | Method and apparatus for selecting, monitoring, and controlling electrically powered devices |
| US20040049499A1 (en) | 2002-08-19 | 2004-03-11 | Matsushita Electric Industrial Co., Ltd. | Document retrieval system and question answering system |
| US20040064305A1 (en) | 2002-09-27 | 2004-04-01 | Tetsuya Sakai | System, method, and program product for question answering |
| US20040122660A1 (en) | 2002-12-20 | 2004-06-24 | International Business Machines Corporation | Creating taxonomies and training data in multiple languages |
| US6763341B2 (en) | 2000-07-28 | 2004-07-13 | Shin'ichiro Okude | Object-oriented knowledge base system |
| US20040243645A1 (en) * | 2003-05-30 | 2004-12-02 | International Business Machines Corporation | System, method and computer program product for performing unstructured information management and automatic text analysis, and providing multiple document views derived from different document tokenizations |
| US6829603B1 (en) | 2000-02-02 | 2004-12-07 | International Business Machines Corp. | System, method and program product for interactive natural dialog |
| US20040249808A1 (en) | 2003-06-06 | 2004-12-09 | Microsoft Corporation | Query expansion using query logs |
| US20040254917A1 (en) * | 2003-06-13 | 2004-12-16 | Brill Eric D. | Architecture for generating responses to search engine queries |
| US20050033711A1 (en) | 2003-08-06 | 2005-02-10 | Horvitz Eric J. | Cost-benefit approach to automatically composing answers to questions by extracting information from large unstructured corpora |
| US20050060301A1 (en) | 2003-09-12 | 2005-03-17 | Hitachi, Ltd. | Question-answering method and question-answering apparatus |
| US20050086045A1 (en) | 2003-10-17 | 2005-04-21 | National Institute Of Information And Communications Technology | Question answering system and question answering processing method |
| US20050086222A1 (en) | 2003-10-16 | 2005-04-21 | Wang Ji H. | Semi-automatic construction method for knowledge base of encyclopedia question answering system |
| US20050114327A1 (en) | 2003-11-21 | 2005-05-26 | National Institute Of Information And Communications Technology | Question-answering system and question-answering processing method |
| US20050143999A1 (en) | 2003-12-25 | 2005-06-30 | Yumi Ichimura | Question-answering method, system, and program for answering question input by speech |
| US6947885B2 (en) | 2000-01-18 | 2005-09-20 | At&T Corp. | Probabilistic model for natural language generation |
| US20050256700A1 (en) | 2004-05-11 | 2005-11-17 | Moldovan Dan I | Natural language question answering system and method utilizing a logic prover |
| US20050289168A1 (en) | 2000-06-26 | 2005-12-29 | Green Edward A | Subject matter context search engine |
| US6983252B2 (en) | 2001-05-04 | 2006-01-03 | Microsoft Corporation | Interactive human-machine interface with a plurality of active states, storing user input in a node of a multinode token |
| US20060053000A1 (en) | 2004-05-11 | 2006-03-09 | Moldovan Dan I | Natural language question answering system and method utilizing multi-modal logic |
| US20060106788A1 (en) | 2004-10-29 | 2006-05-18 | Microsoft Corporation | Computer-implemented system and method for providing authoritative answers to a general information search |
| US20060122834A1 (en) | 2004-12-03 | 2006-06-08 | Bennett Ian M | Emotion detection device & method for use in distributed systems |
| US20060141438A1 (en) | 2004-12-23 | 2006-06-29 | Inventec Corporation | Remote instruction system and method |
| US20060173834A1 (en) | 2005-01-28 | 2006-08-03 | Microsoft Corporation | Table querying |
| US7092928B1 (en) | 2000-07-31 | 2006-08-15 | Quantum Leap Research, Inc. | Intelligent portal engine |
| US20060206481A1 (en) * | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060204945A1 (en) | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060206472A1 (en) | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060235689A1 (en) | 2005-04-13 | 2006-10-19 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US7136909B2 (en) | 2001-12-28 | 2006-11-14 | Motorola, Inc. | Multimodal communication method and apparatus with multimodal profile |
| US20060277165A1 (en) | 2005-06-03 | 2006-12-07 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060282414A1 (en) | 2005-06-10 | 2006-12-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20070022099A1 (en) | 2005-04-12 | 2007-01-25 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20070022109A1 (en) | 2005-07-25 | 2007-01-25 | Tomasz Imielinski | Systems and methods for answering user questions |
| US7181438B1 (en) | 1999-07-21 | 2007-02-20 | Alberti Anemometer, Llc | Database access system |
| US20070073683A1 (en) | 2003-10-24 | 2007-03-29 | Kenji Kobayashi | System and method for question answering document retrieval |
| US20070078842A1 (en) | 2005-09-30 | 2007-04-05 | Zola Scot G | System and method for responding to a user reference query |
| CN1952928A (en) | 2005-10-20 | 2007-04-25 | 梁威 | Computer system to constitute natural language base and automatic dialogue retrieve |
| US20070094285A1 (en) | 2005-10-21 | 2007-04-26 | Microsoft Corporation | Question answering over structured content on the web |
| US7216073B2 (en) | 2001-03-13 | 2007-05-08 | Intelligate, Ltd. | Dynamic natural language understanding |
| US20070118518A1 (en) | 2005-11-18 | 2007-05-24 | The Boeing Company | Text summarization method and apparatus using a multidimensional subspace |
| US20070136246A1 (en) | 2005-11-30 | 2007-06-14 | At&T Corp. | Answer determination for natural language questioning |
| US20070196804A1 (en) | 2006-02-17 | 2007-08-23 | Fuji Xerox Co., Ltd. | Question-answering system, question-answering method, and question-answering program |
| US20070203863A1 (en) | 2006-02-01 | 2007-08-30 | Rakesh Gupta | Meta learning for question classification |
| US20080040321A1 (en) | 2006-08-11 | 2008-02-14 | Yahoo! Inc. | Techniques for searching future events |
| US20080040114A1 (en) | 2006-08-11 | 2008-02-14 | Microsoft Corporation | Reranking QA answers using language modeling |
| US20080077570A1 (en) | 2004-10-25 | 2008-03-27 | Infovell, Inc. | Full Text Query and Search Systems and Method of Use |
| US20080154833A1 (en) | 2006-12-21 | 2008-06-26 | Yahoo! Inc. | Academic filter |
| US20080201132A1 (en) | 2000-11-15 | 2008-08-21 | International Business Machines Corporation | System and method for finding the most likely answer to a natural language question |
| US20090012926A1 (en) | 2006-03-01 | 2009-01-08 | Nec Corporation | Question answering device, question answering method, and question answering program |
| CN101377777A (en) | 2007-09-03 | 2009-03-04 | 北京百问百答网络技术有限公司 | Automatic inquiring and answering method and system |
| US20090070311A1 (en) | 2007-09-07 | 2009-03-12 | At&T Corp. | System and method using a discriminative learning approach for question answering |
| US7519529B1 (en) | 2001-06-29 | 2009-04-14 | Microsoft Corporation | System and methods for inferring informational goals and preferred level of detail of results in response to questions posed to an automated information-retrieval or question-answering service |
| US20090112828A1 (en) | 2006-03-13 | 2009-04-30 | Answers Corporation | Method and system for answer extraction |
| US7558778B2 (en) | 2006-06-21 | 2009-07-07 | Information Extraction Systems, Inc. | Semantic exploration and discovery |
| US7590606B1 (en) | 2003-11-05 | 2009-09-15 | The United States Of America As Represented By The Administrator Of The National Aeronautics And Space Administration (Nasa) | Multi-user investigation organizer |
| US20090248667A1 (en) | 2008-03-31 | 2009-10-01 | Zhaohui Zheng | Learning Ranking Functions Incorporating Boosted Ranking In A Regression Framework For Information Retrieval And Ranking |
| US20090259642A1 (en) | 2008-04-15 | 2009-10-15 | Microsoft Corporation | Question type-sensitive answer summarization |
| US20090287678A1 (en) * | 2008-05-14 | 2009-11-19 | International Business Machines Corporation | System and method for providing answers to questions |
| US20090292687A1 (en) | 2008-05-23 | 2009-11-26 | International Business Machines Corporation | System and method for providing question and answers with deferred type evaluation |
| US20100100546A1 (en) | 2008-02-08 | 2010-04-22 | Steven Forrest Kohler | Context-aware semantic virtual community for communication, information and knowledge management |
| US7730085B2 (en) | 2005-11-29 | 2010-06-01 | International Business Machines Corporation | Method and system for extracting and visualizing graph-structured relations from unstructured text |
| US20100191686A1 (en) | 2009-01-23 | 2010-07-29 | Microsoft Corporation | Answer Ranking In Community Question-Answering Sites |
| US20100325131A1 (en) * | 2009-06-22 | 2010-12-23 | Microsoft Corporation | Assigning relevance weights based on temporal dynamics |
| US20110066587A1 (en) | 2009-09-17 | 2011-03-17 | International Business Machines Corporation | Evidence evaluation system and method based on question answering |
| US20110087656A1 (en) | 2009-10-13 | 2011-04-14 | Electronics And Telecommunications Research Institute | Apparatus for question answering based on answer trustworthiness and method thereof |
| US20110106746A1 (en) | 2009-10-30 | 2011-05-05 | Google Inc. | Affiliate linking |
| US20110145043A1 (en) | 2009-12-15 | 2011-06-16 | David Brian Handel | Method and System for Improving the Truthfulness, Reliability, and Segmentation of Opinion Research Panels |
| US20110185233A1 (en) | 2010-01-25 | 2011-07-28 | International Business Machines Corporation | Automated system problem diagnosing |
| US20130138641A1 (en) | 2009-12-30 | 2013-05-30 | Google Inc. | Construction of text classifiers |
| US20140317099A1 (en) * | 2013-04-23 | 2014-10-23 | Google Inc. | Personalized digital content search |
| US9830392B1 (en) * | 2013-12-18 | 2017-11-28 | BloomReach Inc. | Query-dependent and content-class based ranking |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6618722B1 (en) * | 2000-07-24 | 2003-09-09 | International Business Machines Corporation | Session-history-based recency-biased natural language document search |
-
2011
- 2011-09-22 EP EP11831210.7A patent/EP2622428A4/en not_active Withdrawn
- 2011-09-22 CN CN2011800569905A patent/CN103229120A/en active Pending
- 2011-09-22 US US13/240,140 patent/US9317586B2/en not_active Expired - Fee Related
- 2011-09-22 WO PCT/US2011/052739 patent/WO2012047532A1/en active Application Filing
-
2012
- 2012-09-13 US US13/613,999 patent/US9323831B2/en not_active Expired - Fee Related
-
2016
- 2016-04-18 US US15/131,650 patent/US10216804B2/en active Active
-
2019
- 2019-02-05 US US16/267,688 patent/US11409751B2/en active Active
Patent Citations (96)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3559995A (en) | 1968-04-29 | 1971-02-02 | Psychomantic Game Co | Question answering gameboard and spinner |
| US4594686A (en) | 1979-08-30 | 1986-06-10 | Sharp Kabushiki Kaisha | Language interpreter for inflecting words from their uninflected forms |
| US4599691A (en) | 1982-05-20 | 1986-07-08 | Kokusai Denshin Denwa Co., Ltd. | Tree transformation system in machine translation system |
| US4829423A (en) | 1983-01-28 | 1989-05-09 | Texas Instruments Incorporated | Menu-based natural language understanding system |
| US5513116A (en) | 1988-12-08 | 1996-04-30 | Hallmark Cards Incorporated | Computer controlled machine for vending personalized products or the like |
| US4921427A (en) | 1989-08-21 | 1990-05-01 | Dunn Jeffery W | Educational device |
| US5237502A (en) | 1990-09-04 | 1993-08-17 | International Business Machines Corporation | Method and apparatus for paraphrasing information contained in logical forms |
| US5546316A (en) | 1990-10-22 | 1996-08-13 | Hallmark Cards, Incorporated | Computer controlled system for vending personalized products |
| US5559714A (en) | 1990-10-22 | 1996-09-24 | Hallmark Cards, Incorporated | Method and apparatus for display sequencing personalized social occasion products |
| US5414797A (en) | 1991-05-16 | 1995-05-09 | International Business Machines Corp. | Clustering fuzzy expected value system |
| US5374894A (en) | 1992-08-19 | 1994-12-20 | Hyundai Electronics America | Transition detection circuit |
| US5519608A (en) * | 1993-06-24 | 1996-05-21 | Xerox Corporation | Method for extracting from a text corpus answers to questions stated in natural language by using linguistic analysis and hypothesis generation |
| US5634051A (en) | 1993-10-28 | 1997-05-27 | Teltech Resource Network Corporation | Information management system |
| US5550746A (en) | 1994-12-05 | 1996-08-27 | American Greetings Corporation | Method and apparatus for storing and selectively retrieving product data by correlating customer selection criteria with optimum product designs based on embedded expert judgments |
| US5794050A (en) | 1995-01-04 | 1998-08-11 | Intelligent Text Processing, Inc. | Natural language understanding system |
| US6487545B1 (en) | 1995-05-31 | 2002-11-26 | Oracle Corporation | Methods and apparatus for classifying terminology utilizing a knowledge catalog |
| US6618772B1 (en) | 1996-11-15 | 2003-09-09 | Kim Y. Kao | Method and apparatus for selecting, monitoring, and controlling electrically powered devices |
| US7181438B1 (en) | 1999-07-21 | 2007-02-20 | Alberti Anemometer, Llc | Database access system |
| US6947885B2 (en) | 2000-01-18 | 2005-09-20 | At&T Corp. | Probabilistic model for natural language generation |
| US6829603B1 (en) | 2000-02-02 | 2004-12-07 | International Business Machines Corp. | System, method and program product for interactive natural dialog |
| US20010032211A1 (en) | 2000-04-13 | 2001-10-18 | Hiroshi Kuzumaki | Question answering system and storage medium |
| US20050289168A1 (en) | 2000-06-26 | 2005-12-29 | Green Edward A | Subject matter context search engine |
| US6763341B2 (en) | 2000-07-28 | 2004-07-13 | Shin'ichiro Okude | Object-oriented knowledge base system |
| US7092928B1 (en) | 2000-07-31 | 2006-08-15 | Quantum Leap Research, Inc. | Intelligent portal engine |
| US20080201132A1 (en) | 2000-11-15 | 2008-08-21 | International Business Machines Corporation | System and method for finding the most likely answer to a natural language question |
| US7216073B2 (en) | 2001-03-13 | 2007-05-08 | Intelligate, Ltd. | Dynamic natural language understanding |
| US20020169595A1 (en) | 2001-03-30 | 2002-11-14 | Yevgeny Agichtein | Method for retrieving answers from an information retrieval system |
| US6983252B2 (en) | 2001-05-04 | 2006-01-03 | Microsoft Corporation | Interactive human-machine interface with a plurality of active states, storing user input in a node of a multinode token |
| US7519529B1 (en) | 2001-06-29 | 2009-04-14 | Microsoft Corporation | System and methods for inferring informational goals and preferred level of detail of results in response to questions posed to an automated information-retrieval or question-answering service |
| US20030033287A1 (en) | 2001-08-13 | 2003-02-13 | Xerox Corporation | Meta-document management system with user definable personalities |
| US20030033288A1 (en) | 2001-08-13 | 2003-02-13 | Xerox Corporation | Document-centric system with auto-completion and auto-correction |
| US7136909B2 (en) | 2001-12-28 | 2006-11-14 | Motorola, Inc. | Multimodal communication method and apparatus with multimodal profile |
| US20040049499A1 (en) | 2002-08-19 | 2004-03-11 | Matsushita Electric Industrial Co., Ltd. | Document retrieval system and question answering system |
| US20040064305A1 (en) | 2002-09-27 | 2004-04-01 | Tetsuya Sakai | System, method, and program product for question answering |
| US20040122660A1 (en) | 2002-12-20 | 2004-06-24 | International Business Machines Corporation | Creating taxonomies and training data in multiple languages |
| US7139752B2 (en) | 2003-05-30 | 2006-11-21 | International Business Machines Corporation | System, method and computer program product for performing unstructured information management and automatic text analysis, and providing multiple document views derived from different document tokenizations |
| US20040243645A1 (en) * | 2003-05-30 | 2004-12-02 | International Business Machines Corporation | System, method and computer program product for performing unstructured information management and automatic text analysis, and providing multiple document views derived from different document tokenizations |
| US20040249808A1 (en) | 2003-06-06 | 2004-12-09 | Microsoft Corporation | Query expansion using query logs |
| US20040254917A1 (en) * | 2003-06-13 | 2004-12-16 | Brill Eric D. | Architecture for generating responses to search engine queries |
| US20050033711A1 (en) | 2003-08-06 | 2005-02-10 | Horvitz Eric J. | Cost-benefit approach to automatically composing answers to questions by extracting information from large unstructured corpora |
| US20060294037A1 (en) | 2003-08-06 | 2006-12-28 | Microsoft Corporation | Cost-benefit approach to automatically composing answers to questions by extracting information from large unstructured corpora |
| US20090192966A1 (en) | 2003-08-06 | 2009-07-30 | Microsoft Corporation | Cost-benefit approach to automatically composing answers to questions by extracting information from large unstructured corpora |
| US20050060301A1 (en) | 2003-09-12 | 2005-03-17 | Hitachi, Ltd. | Question-answering method and question-answering apparatus |
| US20050086222A1 (en) | 2003-10-16 | 2005-04-21 | Wang Ji H. | Semi-automatic construction method for knowledge base of encyclopedia question answering system |
| US20050086045A1 (en) | 2003-10-17 | 2005-04-21 | National Institute Of Information And Communications Technology | Question answering system and question answering processing method |
| US20070073683A1 (en) | 2003-10-24 | 2007-03-29 | Kenji Kobayashi | System and method for question answering document retrieval |
| US7590606B1 (en) | 2003-11-05 | 2009-09-15 | The United States Of America As Represented By The Administrator Of The National Aeronautics And Space Administration (Nasa) | Multi-user investigation organizer |
| US20050114327A1 (en) | 2003-11-21 | 2005-05-26 | National Institute Of Information And Communications Technology | Question-answering system and question-answering processing method |
| US20050143999A1 (en) | 2003-12-25 | 2005-06-30 | Yumi Ichimura | Question-answering method, system, and program for answering question input by speech |
| US20060053000A1 (en) | 2004-05-11 | 2006-03-09 | Moldovan Dan I | Natural language question answering system and method utilizing multi-modal logic |
| US20050256700A1 (en) | 2004-05-11 | 2005-11-17 | Moldovan Dan I | Natural language question answering system and method utilizing a logic prover |
| US20080077570A1 (en) | 2004-10-25 | 2008-03-27 | Infovell, Inc. | Full Text Query and Search Systems and Method of Use |
| US20060106788A1 (en) | 2004-10-29 | 2006-05-18 | Microsoft Corporation | Computer-implemented system and method for providing authoritative answers to a general information search |
| US20060122834A1 (en) | 2004-12-03 | 2006-06-08 | Bennett Ian M | Emotion detection device & method for use in distributed systems |
| US20060141438A1 (en) | 2004-12-23 | 2006-06-29 | Inventec Corporation | Remote instruction system and method |
| US20060173834A1 (en) | 2005-01-28 | 2006-08-03 | Microsoft Corporation | Table querying |
| US20060206472A1 (en) | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060206481A1 (en) * | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060204945A1 (en) | 2005-03-14 | 2006-09-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20070022099A1 (en) | 2005-04-12 | 2007-01-25 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US7805303B2 (en) | 2005-04-13 | 2010-09-28 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060235689A1 (en) | 2005-04-13 | 2006-10-19 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060277165A1 (en) | 2005-06-03 | 2006-12-07 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20060282414A1 (en) | 2005-06-10 | 2006-12-14 | Fuji Xerox Co., Ltd. | Question answering system, data search method, and computer program |
| US20070022109A1 (en) | 2005-07-25 | 2007-01-25 | Tomasz Imielinski | Systems and methods for answering user questions |
| US20070078842A1 (en) | 2005-09-30 | 2007-04-05 | Zola Scot G | System and method for responding to a user reference query |
| CN1952928A (en) | 2005-10-20 | 2007-04-25 | 梁威 | Computer system to constitute natural language base and automatic dialogue retrieve |
| US20070094285A1 (en) | 2005-10-21 | 2007-04-26 | Microsoft Corporation | Question answering over structured content on the web |
| US20070118518A1 (en) | 2005-11-18 | 2007-05-24 | The Boeing Company | Text summarization method and apparatus using a multidimensional subspace |
| US7730085B2 (en) | 2005-11-29 | 2010-06-01 | International Business Machines Corporation | Method and system for extracting and visualizing graph-structured relations from unstructured text |
| US20070136246A1 (en) | 2005-11-30 | 2007-06-14 | At&T Corp. | Answer determination for natural language questioning |
| US20070203863A1 (en) | 2006-02-01 | 2007-08-30 | Rakesh Gupta | Meta learning for question classification |
| US20070196804A1 (en) | 2006-02-17 | 2007-08-23 | Fuji Xerox Co., Ltd. | Question-answering system, question-answering method, and question-answering program |
| US20090012926A1 (en) | 2006-03-01 | 2009-01-08 | Nec Corporation | Question answering device, question answering method, and question answering program |
| US20090112828A1 (en) | 2006-03-13 | 2009-04-30 | Answers Corporation | Method and system for answer extraction |
| US7558778B2 (en) | 2006-06-21 | 2009-07-07 | Information Extraction Systems, Inc. | Semantic exploration and discovery |
| US20080040321A1 (en) | 2006-08-11 | 2008-02-14 | Yahoo! Inc. | Techniques for searching future events |
| US20080040114A1 (en) | 2006-08-11 | 2008-02-14 | Microsoft Corporation | Reranking QA answers using language modeling |
| US20080154833A1 (en) | 2006-12-21 | 2008-06-26 | Yahoo! Inc. | Academic filter |
| CN101377777A (en) | 2007-09-03 | 2009-03-04 | 北京百问百答网络技术有限公司 | Automatic inquiring and answering method and system |
| US20090070311A1 (en) | 2007-09-07 | 2009-03-12 | At&T Corp. | System and method using a discriminative learning approach for question answering |
| US20100100546A1 (en) | 2008-02-08 | 2010-04-22 | Steven Forrest Kohler | Context-aware semantic virtual community for communication, information and knowledge management |
| US20090248667A1 (en) | 2008-03-31 | 2009-10-01 | Zhaohui Zheng | Learning Ranking Functions Incorporating Boosted Ranking In A Regression Framework For Information Retrieval And Ranking |
| US20090259642A1 (en) | 2008-04-15 | 2009-10-15 | Microsoft Corporation | Question type-sensitive answer summarization |
| US20090287678A1 (en) * | 2008-05-14 | 2009-11-19 | International Business Machines Corporation | System and method for providing answers to questions |
| US20090292687A1 (en) | 2008-05-23 | 2009-11-26 | International Business Machines Corporation | System and method for providing question and answers with deferred type evaluation |
| US20100191686A1 (en) | 2009-01-23 | 2010-07-29 | Microsoft Corporation | Answer Ranking In Community Question-Answering Sites |
| US20100325131A1 (en) * | 2009-06-22 | 2010-12-23 | Microsoft Corporation | Assigning relevance weights based on temporal dynamics |
| US20110066587A1 (en) | 2009-09-17 | 2011-03-17 | International Business Machines Corporation | Evidence evaluation system and method based on question answering |
| US20110087656A1 (en) | 2009-10-13 | 2011-04-14 | Electronics And Telecommunications Research Institute | Apparatus for question answering based on answer trustworthiness and method thereof |
| US20110106746A1 (en) | 2009-10-30 | 2011-05-05 | Google Inc. | Affiliate linking |
| US20110145043A1 (en) | 2009-12-15 | 2011-06-16 | David Brian Handel | Method and System for Improving the Truthfulness, Reliability, and Segmentation of Opinion Research Panels |
| US20130138641A1 (en) | 2009-12-30 | 2013-05-30 | Google Inc. | Construction of text classifiers |
| US20110185233A1 (en) | 2010-01-25 | 2011-07-28 | International Business Machines Corporation | Automated system problem diagnosing |
| US20140317099A1 (en) * | 2013-04-23 | 2014-10-23 | Google Inc. | Personalized digital content search |
| US9830392B1 (en) * | 2013-12-18 | 2017-11-28 | BloomReach Inc. | Query-dependent and content-class based ranking |
Non-Patent Citations (27)
| Title |
|---|
| "Apache UIMA ConceptMapper Annotator Documentation," Written and maintained by the Apache UIMA Development Community, Version 2.3.1, Copyright 2006, 2011 The Apache Software Foundation, pp. 1-7, http://uima.apache.org/sandbox.html#concept.mapper.annotator. |
| "INDRI Language modeling meets inference networks," http://www.lemurproject.org/indri/, last modified May 23, 2011; pp. 1-2. |
| "Question answering," From Wikipedia, the free encyclopedia, http://en.wikipedia.org/wiki/Question_answering, last modified Sep. 8, 2011. |
| Adar, "SaRAD: a Simple and Robust Abbreviation Dictionary," Bioinformatics, Mar. 2004, pp. 527-533, vol. 20 Issue 4. |
| Aditya Kalyanpur et al., "Leveraging Community-built Knowledge for Type Coercion in Question Answering," Proceedings of ISWC 2011. |
| Balahur, "Going Beyond Traditional QA Systems: Challenges and Keys in Opinions Question Answering," Coling 2010: Poster Volume, pp. 27-35, Beijing, Aug. 2010. |
| Blitzer, Domain Adaptation of Natural Language Processing Systems, Presented to the Faculties of the University of Pennsylvania in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy, 2007. |
| Chang et al., "Creating An Online Dictionary of Abbreviations from MEDLINE," J Am Med Inform Assoc. 2002; 9:612-620. DOI 10.1197/jamia.M1139. |
| Chu-Carroll et al., "In Question-Ansering, Two Heads are Better than One", HLT-NAACL'03, May-Jun. 2003, pp. 24-31, Edmonton, Canada. |
| Cucerzan et al., "Factoid Question Answering over Unstructured and Structured Web Content", In Proceedings of the 14th Text Retrieval Conference TREC 2005, Dec. 31, 2005. |
| Cunningham et al., "The GATE User Guide", http://gate.ac.uk/releases/gate-2.0alpha2-build484/doc/userguide.html, This version of the document is for GATE version 2 alpha 1, of Mar. 2001, pp. 1-13. |
| Delicious, The freshest bookmarks that are flying like hotcakes on Delicious and beyond, Sep. 21, 2011, http://delicious.com/. |
| Ferrucci et al., "Towards the Open Advancement of Question Answering Systems," IBM Technical Report RC24789, Computer Science, Apr. 22, 2009. |
| Ko et al., "Language-independent Probabilistic Answer Ranking for Question Answering", Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, Jun. 2007, pp. 784-791. |
| Moldovan et al., "COGEX: A Logic Prover for Question Answering," Proceedings of HLT-NAACL 2003, May-Jun. 2003, pp. 87-93, Edmonton, Canada. |
| Moldovan et al., "Performance Issues and Error Analysis in an Open-Domain Question Answering System", ACM Transactions on Information Systems, vol. 21, No. 2, Apr. 2003, pp. 133-154. |
| Molla et al., "AnswerFinder at TREC 2004", Proceedings of the 13th Text Retrieval Conference TREC 2004, Dec. 31, 2004. |
| National Center for Biotechnology Information (NCBI), Entrez the Life Sciences Search Engine, Oct. 28, 2009. |
| Pasca, "Question-Driven Semantic Filters for Answer Retrieval", International Journal of Pattern Recognition and Artificial Intelligence (IJPRAI), World Scientific Publishing, SI, vol. 17, No. 5, Aug. 1, 2003, pp. 741-756. |
| Prager et al., "A Multi-Strategy, Multi-Question Approach to Question Answering," In New Directions in Question-Answering, Maybury, M. (Ed.), AAAI Press, 2004. |
| Simmons, "Natural Language Question-Answering Systems: 1969," Communications of the ACM, Jan. 1970, pp. 15-30, 13(1). |
| Strzalkowski et al., "Advances in Open-Domain Question-Answering," Springer, 2006 (background information only). |
| University of Illinois at Urbana-Champaign, Department of Computer Science, Research, 2010, http://cs.illinois.edu/research?report=UIUCDCS-R-2008-2974. |
| Voorhees et al., "Overview of the TREC 2005 Question Answering Track," Proceedings of the Fourteenth Text Retrieval Conference, 2005, Gaithersburg, Maryland. |
| Weinstein et al., "Agents Swarming in Semantic Spaces to Corroborate Hypotheses," AAMAS'04, Jul. 19-23, 2004, New York, New York, USA, Copyright 2004 ACM 1-58113-864-4/04/007. |
| Wikipedia, List of poets from the United States, Sep. 19, 2011, http://en.wikipedia.org/wiki/List_of_poets_from_the_United_States. |
| Wikipedia, List of poets, Sep. 19, 2011, http://en.wikipedia.org/wiki/List_of_poets. |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2012047532A1 (en) | 2012-04-12 |
| EP2622428A4 (en) | 2017-01-04 |
| CN103229120A (en) | 2013-07-31 |
| US20120078889A1 (en) | 2012-03-29 |
| EP2622428A1 (en) | 2013-08-07 |
| US20160232165A1 (en) | 2016-08-11 |
| US9323831B2 (en) | 2016-04-26 |
| US20190171646A1 (en) | 2019-06-06 |
| US10216804B2 (en) | 2019-02-26 |
| US9317586B2 (en) | 2016-04-19 |
| US20130018876A1 (en) | 2013-01-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11409751B2 (en) | Providing answers to questions using hypothesis pruning | |
| US11144544B2 (en) | Providing answers to questions including assembling answers from multiple document segments | |
| US10823265B2 (en) | Providing answers to questions using multiple models to score candidate answers | |
| US10902038B2 (en) | Providing answers to questions using logical synthesis of candidate answers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: INTERNATIONAL BUSINESS MACHINES CORPORATION, NEW YORK Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:CHU-CARROLL, JENNIFER;FERRUCCI, DAVID A.;GONDEK, DAVID C.;AND OTHERS;SIGNING DATES FROM 20160331 TO 20160421;REEL/FRAME:048239/0177 Owner name: INTERNATIONAL BUSINESS MACHINES CORPORATION, NEW Y Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:CHU-CARROLL, JENNIFER;FERRUCCI, DAVID A.;GONDEK, DAVID C.;AND OTHERS;SIGNING DATES FROM 20160331 TO 20160421;REEL/FRAME:048239/0177 |
|
| FEPP | Fee payment procedure |
Free format text: ENTITY STATUS SET TO UNDISCOUNTED (ORIGINAL EVENT CODE: BIG.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: APPLICATION DISPATCHED FROM PREEXAM, NOT YET DOCKETED |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: DOCKETED NEW CASE - READY FOR EXAMINATION |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: NON FINAL ACTION MAILED |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: RESPONSE TO NON-FINAL OFFICE ACTION ENTERED AND FORWARDED TO EXAMINER |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: FINAL REJECTION MAILED |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: RESPONSE AFTER FINAL ACTION FORWARDED TO EXAMINER |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: NOTICE OF ALLOWANCE MAILED -- APPLICATION RECEIVED IN OFFICE OF PUBLICATIONS |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |