CN113343672B - An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging - Google Patents
An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging Download PDFInfo
- Publication number
- CN113343672B CN113343672B CN202110685974.8A CN202110685974A CN113343672B CN 113343672 B CN113343672 B CN 113343672B CN 202110685974 A CN202110685974 A CN 202110685974A CN 113343672 B CN113343672 B CN 113343672B
- Authority
- CN
- China
- Prior art keywords
- corpus
- dictionary
- word
- translation
- word vectors
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000010276 construction Methods 0.000 title abstract description 53
- 239000013598 vector Substances 0.000 claims abstract description 101
- 238000000034 method Methods 0.000 claims abstract description 70
- 238000013507 mapping Methods 0.000 claims abstract description 27
- 238000012549 training Methods 0.000 claims abstract description 24
- 239000011159 matrix material Substances 0.000 claims abstract description 23
- 238000013519 translation Methods 0.000 claims description 69
- 238000000605 extraction Methods 0.000 claims description 3
- 238000007596 consolidation process Methods 0.000 claims 1
- 241000220225 Malus Species 0.000 description 16
- 238000011160 research Methods 0.000 description 4
- 238000012544 monitoring process Methods 0.000 description 3
- 241000234295 Musa Species 0.000 description 2
- 235000021016 apples Nutrition 0.000 description 2
- 235000021015 bananas Nutrition 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 238000003058 natural language processing Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
Description
技术领域technical field
本发明涉及一种基于语料合并的无监督双语词典构建方法,属于无监督双语词典构建领域。The invention relates to an unsupervised bilingual dictionary construction method based on corpus merging, and belongs to the field of unsupervised bilingual dictionary construction.
背景技术Background technique
双语词典构建是利用给定的文本语料构建对应语言的双语词典。双语词典的构建不仅仅是机器翻译的基础,在其他自然语言任务中也有应用,比如跨语言信息发现、跨语言命名实体识别以及跨语言信息安全监测等等。常用的双语词典构建方法是映射方法,即将不同语言的词向量(训练对应语言的文本语料获得的)映射到同一个向量空间中,在这个空间中不同语言中含义相同的词尽可能靠近,进而可以进行双语词典的构建。Bilingual dictionary construction is to use a given text corpus to construct a bilingual dictionary of the corresponding language. The construction of bilingual dictionaries is not only the basis of machine translation, but also has applications in other natural language tasks, such as cross-language information discovery, cross-language named entity recognition, and cross-language information security monitoring. The commonly used bilingual dictionary construction method is the mapping method, which maps the word vectors of different languages (obtained by training the text corpus of the corresponding language) to the same vector space, in which words with the same meaning in different languages are as close as possible, and then Bilingual dictionaries can be constructed.
目前对双语词典构建的方法有很多,其中按照监督程度进行划分,双语词典构建方法可以分为三种:第一种方法是有监督双语词典构建方法,利用平行语料比如人工标注的词典作为监督方式进行映射矩阵的学习,之后利用学习到的映射矩阵将不同语言的词向量映射到同一个空间进行双语词典构建;第二种方法是半监督双语词典构建方法,半监督的方法是利用种子词典或者启发式词典代替原始人工标注的词典进行映射矩阵的学习;第三种是无监督双语词典构建方法,无监督的方法不需要任何双语信息进行监督,直接利用已有的单语语料或者单词词向量进行双语词典的构建。At present, there are many methods for bilingual dictionary construction, which are divided according to the degree of supervision. Bilingual dictionary construction methods can be divided into three types: the first method is a supervised bilingual dictionary construction method, which uses parallel corpus such as manually annotated dictionaries as a supervision method. Carry out the learning of the mapping matrix, and then use the learned mapping matrix to map the word vectors of different languages to the same space for bilingual dictionary construction; the second method is a semi-supervised bilingual dictionary construction method, and the semi-supervised method is to use seed dictionaries or The heuristic dictionary replaces the original manual-labeled dictionary to learn the mapping matrix; the third is the unsupervised bilingual dictionary construction method. The unsupervised method does not require any bilingual information for supervision, and directly uses the existing monolingual corpus or word vectors. Build a bilingual dictionary.
有监督双语词典构建方法在进行训练的过程中需要大规模高质量的平行语料作为监督方式进行训练,然而对于低资源语言来说大规模高质量的词典是难以获取的。半监督方法双语词典构建方法利用种子词典降低了监督程度,虽然降低了对大规模词典的需求,但是由于种子词典的建立需要同源词或者共享单词对语言种类却进行了限制。无监督双语词典构建方法不需要任何程度的监督方式,只需要利用单语语料或者单语词向量就能够进行双语词典的抽取。Supervised bilingual dictionary construction methods require large-scale high-quality parallel corpus as a supervised training method during the training process. However, it is difficult to obtain large-scale high-quality dictionaries for low-resource languages. The semi-supervised method of bilingual dictionary construction uses seed dictionaries to reduce the degree of supervision. Although the demand for large-scale dictionaries is reduced, the language types are limited because the establishment of seed dictionaries requires cognate words or shared words. The unsupervised bilingual dictionary construction method does not require any degree of supervision, and only needs to use monolingual corpus or monolingual word vectors to extract bilingual dictionaries.
平行语料库的难以获取一方面是由于构建平行语料库需要耗费大量的人力物力,另一方面是许多质量较好的平行语料库并不免费开放使用。此外,对于低资源语言来说,少有高质量的平行语料库或者没有对应的平行语料库,但是相关的低资源语言的单语语料却能够在互联网上大量获得。基于以上原因,只需要利用单语语料的无监督双语词典构建方法逐渐成为研究热点。The difficulty of obtaining parallel corpora is due to the fact that building a parallel corpus requires a lot of manpower and material resources, and on the other hand, many parallel corpora with good quality are not free and open for use. In addition, for low-resource languages, there are few or no high-quality parallel corpora, but related monolingual corpora of low-resource languages can be obtained in large quantities on the Internet. Based on the above reasons, the unsupervised bilingual dictionary construction method that only needs to use monolingual corpus has gradually become a research hotspot.
目前无监督双语词典的构建方法主要有两种:At present, there are two main methods for constructing unsupervised bilingual dictionaries:
(1)是利用对抗学习的方法进行无监督双语词典构建,利用判别器来区分映射的源向量和目标向量,训练生成器(映射矩阵)来欺骗判别器。(1) is to use the method of adversarial learning for unsupervised bilingual dictionary construction, use the discriminator to distinguish the mapped source vector and target vector, and train the generator (mapping matrix) to deceive the discriminator.
(2)是根据词向量结构相似性等方法进行初始词典的构建,之后迭代自学习方法学习映射。(2) The initial dictionary is constructed according to the similarity of the word vector structure, and then the iterative self-learning method learns the mapping.
发明内容Contents of the invention
本发明的目的是为了解决低资源语言平行语料库匮乏导致的双语词典构建代价过高的问题,以及提高基于无监督双语构建的词典的性能的问题,而提出的一种基于语料合并的无监督双语词典构建方法The purpose of the present invention is to solve the problem of high cost of bilingual dictionary construction caused by the lack of parallel corpora of low-resource languages, and to improve the performance of dictionaries based on unsupervised bilingual construction. Dictionary construction method
一种基于语料合并的无监督双语词典构建方法,基于语料合并的无监督双语词典构建方法包括以下步骤:A kind of unsupervised bilingual dictionary construction method based on corpus merging, the unsupervised bilingual dictionary construction method based on corpus merging comprises the following steps:
步骤一、根据源语言单语语料和目标语言单语语料训练得到各自对应的词向量;Step 1. According to the source language monolingual corpus and the target language monolingual corpus training, corresponding word vectors are obtained;
步骤二、计算步骤一得到的词向量对应的两个自相似度矩阵,利用自相似度矩构建初始化词典D0,并根据初始化词典D0迭代自学习方法得到映射矩阵W;Step 2, calculating two self-similarity matrices corresponding to the word vectors obtained in step 1, using the self-similarity moment to construct the initialization dictionary D0, and obtaining the mapping matrix W according to the iterative self-learning method of the initialization dictionary D0;
步骤三、根据步骤二得到的映射矩阵W,将源语言词向量映射到目标语言词向量空间中,并据此抽取词典;Step 3. According to the mapping matrix W obtained in step 2, the source language word vector is mapped to the target language word vector space, and a dictionary is extracted accordingly;
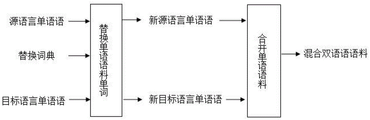
步骤四、根据步骤三得到的词典替换原来单语语料的单词并混合两个单语语料得到混合语料;Step 4, replace the words of the original monolingual corpus according to the dictionary obtained in step 3 and mix two monolingual corpora to obtain a mixed corpus;
步骤五、利用词向量训练方法训练步骤四得到的混合语料并获取混合语料的词向量;Step 5, using the word vector training method to train the mixed corpus obtained in step 4 and obtain the word vector of the mixed corpus;
步骤六、将步骤五中得到混合词向量分开得到新的源语言和目标语言词向量;Step 6, separate the mixed word vectors obtained in step 5 to obtain new source language and target language word vectors;
步骤七、将步骤六得到的新的源语言和目标语言词向量作为输入,重新进行步骤二的过程得到新的映射矩阵W1,利用W1将不同语言的词向量映射到同一个向量空间,在该向量空间中可以根据相似度构建词典。Step 7. Take the new source language and target language word vectors obtained in step 6 as input, repeat the process of step 2 to obtain a new mapping matrix W1, and use W1 to map word vectors in different languages to the same vector space. In this In the vector space, dictionaries can be constructed according to the similarity.
进一步的,步骤三中,利用步骤二得到的映射矩阵进行词典抽取,具体过程为:Further, in step 3, the mapping matrix obtained in step 2 is used for dictionary extraction, and the specific process is as follows:
步骤三一、利用步骤二得到的映射矩阵W,将源语言词向量映射到目标语言向量空间中,在目标语言向量空间中,寻找与源语言单词最近的目标单词作为源语言单词的翻译,将源语言单词和该源语言单词的翻译形成翻译对;Step 31. Use the mapping matrix W obtained in step 2 to map the source language word vector to the target language vector space. In the target language vector space, find the target word closest to the source language word as the translation of the source language word. A source language word and a translation of that source language word form a translation pair;
步骤三二、将步骤三一得到的翻译对,按照翻译对两个单词之间相似度的大小,从大到小进行排序,抽取排序后翻译对的前1500个翻译对作为替换词典。Step 32: sort the translation pairs obtained in step 31 in descending order according to the similarity between the two words in the translation pair, and extract the first 1500 translation pairs of the sorted translation pairs as replacement dictionaries.
进一步的,步骤四中,利用步骤三抽取得到的词典对原来的单语语料进行单词替换与语料合并,具体过程为:Further, in Step 4, use the dictionary extracted in Step 3 to perform word replacement and corpus merging on the original monolingual corpus. The specific process is as follows:
步骤四一、将步骤三二得到的翻译对联结成一个整体,即翻译联结对,具体的,将翻译对中的源语言单词和目标语言单词联结成一个整体得到对应的翻译联结对,将步骤三二中的1500个翻译对联结成对应的1500个翻译联结对;Step 41. Combine the translation pairs obtained in Step 3 and 2 into a whole, that is, the translation connection pair. Specifically, combine the source language words and target language words in the translation pair into a whole to obtain the corresponding translation connection pair. The 1500 translation pairs in 32 are linked into the corresponding 1500 translation link pairs;
步骤四二、利用步骤三得到的词典和步骤四一得到的翻译联结对,对原始单语语料进行单词替换,并且将替换完的单语语料进行合并。Step 42: Use the dictionary obtained in step 3 and the translation pair obtained in step 41 to perform word replacement on the original monolingual corpus, and merge the replaced monolingual corpus.
进一步的,步骤六中,将步骤五得到的源语言与目标语言词向量分离开,具体过程为:Further, in step six, the source language and target language word vectors obtained in step five are separated, and the specific process is as follows:
步骤六一、将步骤五获得的源语言和目标语言词向量分开,同时将联结翻译对的单词分开为对应的源语言单词词向量和目标语言单词词向量。Step 61: Separate the source language word vectors and target language word vectors obtained in step 5, and at the same time separate the words associated with the translation pair into corresponding source language word word vectors and target language word word vectors.
本发明的有以下优点:The present invention has the following advantages:
本发明相关研究不仅对机器翻译具有帮助,对于其他的跨语言自然语言处理任务尤其是有关低资源语言的研究任务具有促进作用,例如跨语言信息发现、跨语言命名实体识别以及跨语言信息安全监测等等。为了提高构建的双语词典质量,本发明利用替换单词与合并单语语料提升词向量的质量,进而可以提升无监督方法构建的词典的质量。为了解决低资源语言平行语料匮乏的问题,本发明提出了一种基于合并语料的无监督双语词典构建方法。本发明提出的方法实现简单,只利用单语语料就可以进行双语词典的构建,减轻了对平行语料库的依赖,同时利用单词替换和合并语料的方法提升了构建的双语词典的质量。总的来说,该方法提出了一种基于合并语料的无监督双语词典构建方法。The research related to the present invention is not only helpful to machine translation, but also has a promoting effect on other cross-language natural language processing tasks, especially research tasks on low-resource languages, such as cross-language information discovery, cross-language named entity recognition, and cross-language information security monitoring wait. In order to improve the quality of the constructed bilingual dictionary, the present invention utilizes replacing words and merging monolingual corpus to improve the quality of word vectors, thereby improving the quality of the dictionary constructed by the unsupervised method. In order to solve the problem of lack of parallel corpus in low-resource languages, the present invention proposes an unsupervised bilingual dictionary construction method based on combined corpus. The method proposed by the invention is simple to implement, and the bilingual dictionary can be constructed only by using monolingual corpus, which reduces the dependence on parallel corpora, and simultaneously uses the method of word replacement and merging corpus to improve the quality of the constructed bilingual dictionary. Overall, the method proposes a method for unsupervised bilingual dictionary construction based on pooled corpora.
在本发明提出了一种基于合并语料的无监督双语词典构建方法。通过分析无监督双语词典构建方法与词向量训练方法的特性,利用合并语料的方法提升不同语言词向量的质量,进而提升构建词典的质量。本发明基于现有的无监督双语词典构建方法等,利用单词替换与合并语料的方法提升构建词典的性能。The present invention proposes an unsupervised bilingual dictionary construction method based on merging corpus. By analyzing the characteristics of the unsupervised bilingual dictionary construction method and word vector training method, the method of merging corpora is used to improve the quality of word vectors in different languages, thereby improving the quality of dictionary construction. The present invention is based on the existing unsupervised bilingual dictionary construction method, etc., and uses the method of word replacement and merging corpus to improve the performance of dictionary construction.
本发明在抽取替换语料的词典中,对抽取词典的翻译对之间的相似度值按照从大到小排序后,抽取靠前的翻译对作为替换单语语料中单词的依据。为了提高替换语料单词词典的准确度,考虑了相似度值越大的翻译对,一般翻译的准确度越高的信息。In the dictionary of the extracted replacement corpus, the invention sorts the similarity values between the translation pairs of the extracted dictionary from large to small, and then extracts the top translation pairs as the basis for replacing words in the monolingual corpus. In order to improve the accuracy of the replacement corpus word dictionary, the translation pair with a larger similarity value is considered, and generally the higher the accuracy of the translation is.
本发明是利用替换单词与合并语料的方法来提升不同语言词向量之间的相似度,利用抽取的词典翻译对替换原来单语语料中的单词,之后合并替换单词后的单语语料。考虑到当前词向量训练方法大都需要考虑到上下文信息,训练混合语料不仅能够使词典翻译对中的单词词向量一致,还能够使对应翻译对中单词的上下文单词的词向量更加接近,进而能够提升不同语言中词向量的相似度。The present invention uses the method of replacing words and merging corpus to improve the similarity between word vectors in different languages, uses extracted dictionary translation pairs to replace words in the original monolingual corpus, and then merges and replaces the monolingual corpus. Considering that most of the current word vector training methods need to take context information into account, training mixed corpus can not only make the word vectors in the dictionary translation pairs consistent, but also make the word vectors of the context words corresponding to the words in the translation pairs closer, thereby improving Similarity of word vectors in different languages.
本发明是利用合并单语语料的方法来进行无监督双语词典构建,本发明的方法充分利用了词向量训练方法中对上下文信息依赖的信息,以及基于当前无监督词典构建方法结果中翻译对的相似度值越大,翻译对的越准确的信息,对单语语料中的单词进行替换同时合并替换单词后的单语语料。对训练词向量的方法和无监督双语词典构建方法的特性进行了充分的利用。The present invention uses the method of merging monolingual corpus to carry out unsupervised bilingual dictionary construction. The method of the present invention makes full use of the information dependent on context information in the word vector training method, and the translation pair in the result based on the current unsupervised dictionary construction method. The larger the similarity value, the more accurate the translation is. Replace the words in the monolingual corpus and merge the monolingual corpus after replacing the words. The method of training word vectors and the characteristics of the unsupervised bilingual dictionary construction method are fully utilized.
本发明主要是针对低资源语言平行语料匮乏的问题提出的方法,考虑了词向量训练方法和当前无监督双语词典构建方法的特性,对于单语语料进行了充分的利用。经过实验,发现相较于当前无监督双语词典构建方法,该方法在多种语言上构建的词典的准确度都有提升。The present invention mainly proposes a method for the lack of parallel corpus in low-resource languages, and takes into account the characteristics of the word vector training method and the current unsupervised bilingual dictionary construction method, and makes full use of the monolingual corpus. After experiments, it is found that compared with the current unsupervised bilingual dictionary construction method, the accuracy of the dictionary constructed by this method in multiple languages has been improved.
附图说明Description of drawings
图1为本发明的一种基于语料合并的无监督双语词典构建方法的主要过程流程图;Fig. 1 is the main process flowchart of a kind of unsupervised bilingual dictionary construction method based on corpus merger of the present invention;
图2为步骤四提出的替换单词并合并语料的示例说明图。Fig. 2 is an explanatory diagram of an example of replacing words and merging corpus proposed in step 4.
具体实施方式detailed description
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
本发明提出了一种合并语料的无监督双语词典构建方法的实施方式,具体是按照以下步骤制备的:The present invention proposes an embodiment of an unsupervised bilingual dictionary construction method for merging corpus, which is specifically prepared according to the following steps:
步骤一、根据源语言单语语料和目标语言单语语料训练得到各自对应的词向量;Step 1. According to the source language monolingual corpus and the target language monolingual corpus training, corresponding word vectors are obtained;
步骤二、计算步骤一得到的词向量对应的两个自相似度矩阵,利用自相似度矩构建初始化词典D0,并根据初始化词典D0迭代自学习方法得到映射矩阵WStep 2. Calculate the two self-similarity matrices corresponding to the word vector obtained in step 1. Use the self-similarity moment to construct the initialization dictionary D0, and obtain the mapping matrix W according to the iterative self-learning method of the initialization dictionary D0
步骤三、根据步骤二得到的映射矩阵W,将源语言词向量映射到目标语言词向量空间中,并据此抽取词典;Step 3. According to the mapping matrix W obtained in step 2, the source language word vector is mapped to the target language word vector space, and a dictionary is extracted accordingly;
步骤四、根据步骤三得到的词典替换原来单语语料的单词并混合两个单语语料得到混合语料;Step 4, replace the words of the original monolingual corpus according to the dictionary obtained in step 3 and mix two monolingual corpora to obtain a mixed corpus;
步骤五、利用词向量训练方法训练步骤四得到的混合语料并获取混合语料的词向量;Step 5, using the word vector training method to train the mixed corpus obtained in step 4 and obtain the word vector of the mixed corpus;
步骤六、将步骤五中得到混合词向量分开得到新的源语言和目标语言词向量;Step 6, separate the mixed word vectors obtained in step 5 to obtain new source language and target language word vectors;
步骤七、将步骤六得到的新的源语言和目标语言词向量作为输入,重新进行步骤二的过程得到新的映射矩阵W1。利用W1可以将不同语言的词向量映射到同一个向量空间,在该向量空间中可以根据相似度构建词典。Step 7: Take the new source language and target language word vectors obtained in Step 6 as input, and repeat the process of Step 2 to obtain a new mapping matrix W1. Using W1, word vectors in different languages can be mapped to the same vector space, in which a dictionary can be constructed according to the similarity.
具体的,本发明不仅对机器翻译具有帮助,对于其他的跨语言自然语言处理任务尤其是有关低资源语言的研究任务具有促进作用,例如跨语言信息发现、跨语言命名实体识别以及跨语言信息安全监测等等。为了提高构建的双语词典质量,本实施方式利用替换单词与合并单语语料提升词向量的质量,进而可以提升无监督方法构建的词典的质量。为了解决低资源语言平行语料匮乏的问题,本实施方式提出了一种基于合并语料的无监督双语词典构建方法。本实施方式提出的方法实现简单,只利用单语语料就可以进行双语词典的构建,减轻了对平行语料库的依赖,同时利用单词替换和合并语料的方法提升了构建的双语词典的质量。总的来说,本方法提出了一种基于合并语料的无监督双语词典构建方法。Specifically, the present invention not only helps machine translation, but also promotes other cross-language natural language processing tasks, especially research tasks related to low-resource languages, such as cross-language information discovery, cross-language named entity recognition, and cross-language information security. monitoring and more. In order to improve the quality of the constructed bilingual dictionary, this embodiment improves the quality of word vectors by replacing words and merging monolingual corpus, thereby improving the quality of the dictionary constructed by the unsupervised method. In order to solve the problem of lack of parallel corpora in low-resource languages, this embodiment proposes an unsupervised bilingual dictionary construction method based on combined corpora. The method proposed in this embodiment is simple to implement, and a bilingual dictionary can be constructed by using only monolingual corpus, which reduces the dependence on parallel corpora, and at the same time uses the method of word replacement and merging corpus to improve the quality of the constructed bilingual dictionary. Overall, this method proposes an unsupervised bilingual dictionary construction method based on pooled corpora.
在本实施方式提出了一种基于合并语料的无监督双语词典构建方法。通过分析无监督双语词典构建方法与词向量训练方法的特性,利用合并语料的方法提升不同语言词向量的质量,进而提升构建词典的质量。本实施方式基于现有的无监督双语词典构建方法,利用单词替换与合并语料的方法提升构建词典的性能。In this embodiment, an unsupervised bilingual dictionary construction method based on combined corpus is proposed. By analyzing the characteristics of the unsupervised bilingual dictionary construction method and word vector training method, the method of merging corpora is used to improve the quality of word vectors in different languages, thereby improving the quality of dictionary construction. This embodiment is based on the existing unsupervised bilingual dictionary construction method, and uses word replacement and corpus merging methods to improve the performance of dictionary construction.
本实施方式在抽取替换语料的词典中,对抽取词典的翻译对之间的相似度值按照从大到小排序后,抽取靠前的翻译对作为替换单语语料中单词的依据。为了提高替换语料单词词典的准确度,考虑了相似度值越大的翻译对,一般翻译的准确度越高的信息。In this embodiment, in the extracted dictionary of the replacement corpus, the similarity values between the translation pairs of the extracted dictionary are sorted from large to small, and the top translation pairs are extracted as the basis for replacing words in the monolingual corpus. In order to improve the accuracy of the replacement corpus word dictionary, the translation pair with a larger similarity value is considered, and generally the higher the accuracy of the translation is.
本实施方式是利用替换单词与合并语料的方法来提升不同语言词向量之间的相似度,利用抽取的词典翻译对替换原来单语语料中的单词,之后合并替换单词后的单语语料。考虑到当前词向量训练方法大都需要考虑到上下文信息,训练混合语料不仅能够使词典翻译对中的单词词向量一致,还能够使对应翻译对中单词的上下文单词的词向量更加接近,进而能够提升不同语言中词向量的相似度。In this embodiment, the method of replacing words and merging corpora is used to improve the similarity between word vectors in different languages, and the extracted dictionary-translation pairs are used to replace the words in the original monolingual corpus, and then the monolingual corpus after replacing the words is merged. Considering that most of the current word vector training methods need to take context information into account, training mixed corpus can not only make the word vectors in the dictionary translation pairs consistent, but also make the word vectors of the context words corresponding to the words in the translation pairs closer, thereby improving Similarity of word vectors in different languages.
本实施方式是利用合并单语语料的方法来进行无监督双语词典构建,本实施方式的方法充分利用了词向量训练方法中对上下文信息依赖的信息,以及基于当前无监督词典构建方法结果中翻译对的相似度值越大,翻译对的越准确的信息,对单语语料中的单词进行替换同时合并替换单词后的单语语料。对训练词向量的方法和无监督双语词典构建方法的特性进行了充分的利用。This embodiment uses the method of merging monolingual corpus to carry out unsupervised bilingual dictionary construction. The method of this embodiment makes full use of the information dependent on context information in the word vector training method, and translates in the results based on the current unsupervised dictionary construction method. The larger the similarity value of the pair, the more accurate the translation is. The words in the monolingual corpus are replaced and the monolingual corpus after the word is replaced is merged. The method of training word vectors and the characteristics of the unsupervised bilingual dictionary construction method are fully utilized.
本实施方式主要是针对低资源语言平行语料匮乏的问题提出的方法,考虑了词向量训练方法和当前无监督双语词典构建方法的特性,对于单语语料进行了充分的利用。经过实验,发现相较于当前无监督双语词典构建方法,该方法在多种语言上构建的词典的准确度都有提升。This embodiment is mainly a method proposed for the lack of parallel corpora in low-resource languages. It takes into account the characteristics of the word vector training method and the current unsupervised bilingual dictionary construction method, and fully utilizes the monolingual corpus. After experiments, it is found that compared with the current unsupervised bilingual dictionary construction method, the accuracy of the dictionary constructed by this method in multiple languages has been improved.
进一步的,利用步骤二中得到的映射矩阵W可以将源语言词向量空间到目标语言词向量空间中,从而可以在目标向量空间进行抽取词典;但是在抽取词典的时候,抽取得到的词典准确度不高;然而对于本发明,对翻译对的相似度值进行排序,抽取靠前的词典,因此:Further, using the mapping matrix W obtained in step 2, the source language word vector space can be transferred to the target language word vector space, so that the dictionary can be extracted in the target vector space; but when extracting the dictionary, the accuracy of the extracted dictionary is is not high; however, for the present invention, the similarity values of the translation pairs are sorted, and the front dictionary is extracted, so:
步骤三一、利用步骤二得到的映射矩阵W,将源语言词向量映射到目标语言向量空间中,在这个空间中寻找与源语言单词最近的目标单词作为该源语言单词的翻译。Step 31: Use the mapping matrix W obtained in step 2 to map the source language word vector into the target language vector space, and find the target word closest to the source language word in this space as the translation of the source language word.
步骤三二、将步骤三一得到的翻译对,按照翻译对两个单词之间相似度的大小,从大到小进行排序,抽取排序后翻译对的前1500个翻译对作为替换词典;Step 32, the translation pairs obtained in step 31 are sorted according to the similarity between the two words in the translation pair, and the first 1500 translation pairs of the sorted translation pairs are extracted as replacement dictionaries;
进一步的,参照图2所示(其中,词典是由步骤三获得的),步骤四利用步骤三抽取得到的词典对原来的单语语料进行单词替换与语料合并:Further, as shown in Fig. 2 (wherein, the dictionary is obtained by step 3), step 4 uses the dictionary extracted in step 3 to perform word replacement and corpus merging on the original monolingual corpus:
步骤四一、将步骤三二得到的翻译对联结成一个整体,即翻译联结对,具体的,将翻译对中的源语言单词和目标语言单词联结成一个整体得到对应的翻译联结对,将步骤三二中的1500个翻译对联结成对应的1500个翻译联结对,例如:apple苹果是一对翻译对,联结成一个整体apple***苹果。将词典中的所有翻译对都联结成为一对翻译联结对。Step 41. Combine the translation pairs obtained in Step 3 and 2 into a whole, that is, the translation connection pair. Specifically, combine the source language words and target language words in the translation pair into a whole to obtain the corresponding translation connection pair. The 1500 translation pairs in 32 are connected into corresponding 1500 translation connection pairs, for example: apple apple is a pair of translation pairs, which are connected into a whole apple***apple. Concatenates all translation pairs in the dictionary into a translation concatenation pair.
步骤四二、利用步骤三得到的词典和步骤四一得到的翻译联结对,对原始单语语料进行单词替换,并且将替换完的单语语料进行合并,例如:Step 42. Use the dictionary obtained in step 3 and the translation connection pair obtained in step 41 to replace words in the original monolingual corpus, and merge the replaced monolingual corpus, for example:
源语言语料:Source language corpus:
我喜欢吃苹果,她喜欢吃香蕉。I like apples and she likes bananas.
目标语言语料:Target language corpus:
Here is an apple,do you want to eat it?Here is an apple, do you want to eat it?
词典:dictionary:
apple苹果apple apple
词典对应的翻译联结对:The translation association pair corresponding to the dictionary:
apple***苹果apple***apple
替换单词并合并单语语料得到的混合语料:Mixed corpus obtained by replacing words and merging monolingual corpora:
我喜欢吃apple***苹果,她喜欢吃香蕉。I like to eat apple*** apples, and she likes to eat bananas.
Here is an apple***苹果,do you want to eat it?Here is an apple***apple, do you want to eat it?
通过以上方式对单语语料的单词进行翻译联结对替换和语料合并得到混合语料进行下一步的处理。Through the above method, the words in the monolingual corpus are translated and connected, and the mixed corpus obtained by replacing and corpus is processed in the next step.
进一步的,将步骤五中得到的混合词向量分开,保证了抽取词典中翻译对之间词向量的一致性,因此:Further, separating the mixed word vectors obtained in step 5 ensures the consistency of word vectors between translation pairs in the extracted dictionary, so:
步骤六一、将步骤五获得的源语言和目标语言词向量分开,同时将联结翻译对的单词分开为对应的源语言单词词向量和目标语言单词词向量,例如:Step 61. Separate the source language and target language word vectors obtained in step 5, and at the same time separate the words associated with the translation pair into corresponding source language word vectors and target language word vectors, for example:
混合语料得到的词向量:Word vector obtained from mixed corpus:
多(0.0640.1450.942)Multi (0.0640.1450.942)
the(-0.080-1.0390.094)the(-0.080-1.0390.094)
apple***苹果(-1.345-0.7860.684)apple*** Apple (-1.345-0.7860.684)
分离得到的源语言词向量:The source language word vector obtained by separation:
苹果(-1.345-0.7860.684)Apple (-1.345-0.7860.684)
多(0.0640.1450.942)Multi (0.0640.1450.942)
分离得到的目标语言词向量:The separated target language word vector:
apple(-1.345-0.7860.684)apple (-1.345-0.7860.684)
the(-0.080-1.0390.094)the(-0.080-1.0390.094)
以上实施示例只是用于帮助理解本发明的方法及其核心思想,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。The above implementation examples are only used to help understand the method of the present invention and its core idea. For those of ordinary skill in the art, according to the idea of the present invention, some improvements and modifications can be made in the specific implementation and application range. These improvements And retouching should also be regarded as the protection scope of the present invention.
Claims (2)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110685974.8A CN113343672B (en) | 2021-06-21 | 2021-06-21 | An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110685974.8A CN113343672B (en) | 2021-06-21 | 2021-06-21 | An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113343672A CN113343672A (en) | 2021-09-03 |
| CN113343672B true CN113343672B (en) | 2022-12-16 |
Family
ID=77477840
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110685974.8A Active CN113343672B (en) | 2021-06-21 | 2021-06-21 | An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113343672B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114169345B (en) * | 2021-10-28 | 2025-05-02 | 合肥工业大学 | Japanese-Chinese machine translation method and system using cognates |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006031511A (en) * | 2004-07-20 | 2006-02-02 | Nippon Telegr & Teleph Corp <Ntt> | Translation model generation apparatus and method |
| CN105446958A (en) * | 2014-07-18 | 2016-03-30 | 富士通株式会社 | Word aligning method and device |
| CN108960317A (en) * | 2018-06-27 | 2018-12-07 | 哈尔滨工业大学 | Across the language text classification method with Classifier combination training is indicated based on across language term vector |
| CN110110061A (en) * | 2019-04-26 | 2019-08-09 | 同济大学 | Low-resource languages entity abstracting method based on bilingual term vector |
| CN110297903A (en) * | 2019-06-11 | 2019-10-01 | 昆明理工大学 | A kind of across language word embedding grammar based on not reciprocity corpus |
| CN110598221A (en) * | 2019-08-29 | 2019-12-20 | 内蒙古工业大学 | A Method of Improving the Quality of Mongolian-Chinese Translation Using Generative Adversarial Networks to Construct Mongolian-Chinese Parallel Corpus |
| CN111753557A (en) * | 2020-02-17 | 2020-10-09 | 昆明理工大学 | A Chinese-Vietnamese Unsupervised Neural Machine Translation Method Based on EMD Minimized Bilingual Dictionary |
| CN112580333A (en) * | 2020-12-21 | 2021-03-30 | 安徽七天教育科技有限公司 | English composition scoring method aiming at image recognition |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109597988B (en) * | 2018-10-31 | 2020-04-28 | 清华大学 | Cross-language lexical semantic prediction method, device and electronic device |
| CN111581386A (en) * | 2020-05-08 | 2020-08-25 | 深圳市第五空间网络科技有限公司 | Construction method, device, equipment and medium of multi-output text classification model |
| CN111881334A (en) * | 2020-07-15 | 2020-11-03 | 浙江大胜达包装股份有限公司 | Keyword-to-enterprise retrieval method based on semi-supervised learning |
| CN112287695A (en) * | 2020-09-18 | 2021-01-29 | 昆明理工大学 | Cross-language bilingual pre-training and Bi-LSTM-based Chinese-character-cross parallel sentence pair extraction method |
-
2021
- 2021-06-21 CN CN202110685974.8A patent/CN113343672B/en active Active
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006031511A (en) * | 2004-07-20 | 2006-02-02 | Nippon Telegr & Teleph Corp <Ntt> | Translation model generation apparatus and method |
| CN105446958A (en) * | 2014-07-18 | 2016-03-30 | 富士通株式会社 | Word aligning method and device |
| CN108960317A (en) * | 2018-06-27 | 2018-12-07 | 哈尔滨工业大学 | Across the language text classification method with Classifier combination training is indicated based on across language term vector |
| CN110110061A (en) * | 2019-04-26 | 2019-08-09 | 同济大学 | Low-resource languages entity abstracting method based on bilingual term vector |
| CN110297903A (en) * | 2019-06-11 | 2019-10-01 | 昆明理工大学 | A kind of across language word embedding grammar based on not reciprocity corpus |
| CN110598221A (en) * | 2019-08-29 | 2019-12-20 | 内蒙古工业大学 | A Method of Improving the Quality of Mongolian-Chinese Translation Using Generative Adversarial Networks to Construct Mongolian-Chinese Parallel Corpus |
| CN111753557A (en) * | 2020-02-17 | 2020-10-09 | 昆明理工大学 | A Chinese-Vietnamese Unsupervised Neural Machine Translation Method Based on EMD Minimized Bilingual Dictionary |
| CN112580333A (en) * | 2020-12-21 | 2021-03-30 | 安徽七天教育科技有限公司 | English composition scoring method aiming at image recognition |
Non-Patent Citations (6)
| Title |
|---|
| Constrained recombination in an example-based machine translation system;Gavrila Monica;《Proceedings of the 15th Annual conference of the European Association for Machine Translation》;20111231;1-8 * |
| On the Limitations of Unsupervised Bilingual Dictionary Induction;Sebastian Ruder 等;《网页在线公开:https://arxiv.org/abs/1805.03620》;20180509;1-11 * |
| Unsupervised sentiment analysis for code-mixed data;Yadav Siddharth 等;《网页在线公开:https://arxiv.org/abs/2001.11384》;20200120;1-8 * |
| 基于混合余弦相似度的中文文本层次关系挖掘;董洋溢 等;《计算机应用研究》;20160715;第34卷(第5期);1406-1409 * |
| 基于混合语料的无监督双语词典抽取;韩梦凡 等;《智能计算机与应用》;20210801;第11卷(第8期);164-166 * |
| 基于非平行语料的双语词典构建;张檬 等;《中国科学:信息科学》;20180520;第48卷(第5期);564-573 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113343672A (en) | 2021-09-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111382580B (en) | Encoder-decoder framework pre-training method for neural machine translation | |
| CN108960317B (en) | Cross-language text classification method based on word vector representation and classifier combined training | |
| CN110232186A (en) | The knowledge mapping for merging entity description, stratification type and text relation information indicates learning method | |
| CN108681537A (en) | Chinese entity linking method based on neural network and word vector | |
| CN108628970A (en) | A kind of biomedical event joint abstracting method based on new marking mode | |
| CN106844352A (en) | Word prediction method and system based on neural machine translation system | |
| CN111506728B (en) | Hierarchical structure text automatic classification method based on HD-MSCNN | |
| CN103020167B (en) | A kind of computer Chinese file classification method | |
| CN104991890A (en) | Method for constructing Vietnamese dependency tree bank on basis of Chinese-Vietnamese vocabulary alignment corpora | |
| CN110516239B (en) | Segmentation pooling relation extraction method based on convolutional neural network | |
| CN112347761B (en) | BERT-based drug relation extraction method | |
| CN106844356B (en) | Method for improving English-Chinese machine translation quality based on data selection | |
| CN113657122B (en) | A Mongolian-Chinese machine translation method integrating pseudo-parallel corpus with transfer learning | |
| CN113377953B (en) | Entity fusion and classification method based on PALC-DCA model | |
| CN112446213A (en) | Text corpus expansion method | |
| CN110457715A (en) | Chinese-Vietnamese neural machine translation out-of-collection word processing method integrated into lexicon | |
| CN113343672B (en) | An Unsupervised Bilingual Dictionary Construction Method Based on Corpus Merging | |
| CN101794378A (en) | Rubbish image filtering method based on image encoding | |
| CN115828931A (en) | Chinese and English semantic similarity calculation method for paragraph-level text | |
| CN104134017B (en) | Protein interaction relationship pair extraction method based on compact character representation | |
| CN109815503A (en) | A Human-Computer Interaction Translation Method | |
| CN115496079B (en) | Chinese translation method and device | |
| CN117743598A (en) | Method and system for constructing technical standard knowledge graph of power distribution network | |
| CN114611487B (en) | Unsupervised Thai dependency syntax analysis method based on dynamic word embedding alignment | |
| CN117332081A (en) | A Mongolian-Chinese cross-language sentiment analysis method based on knowledge sharing and adaptive learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |