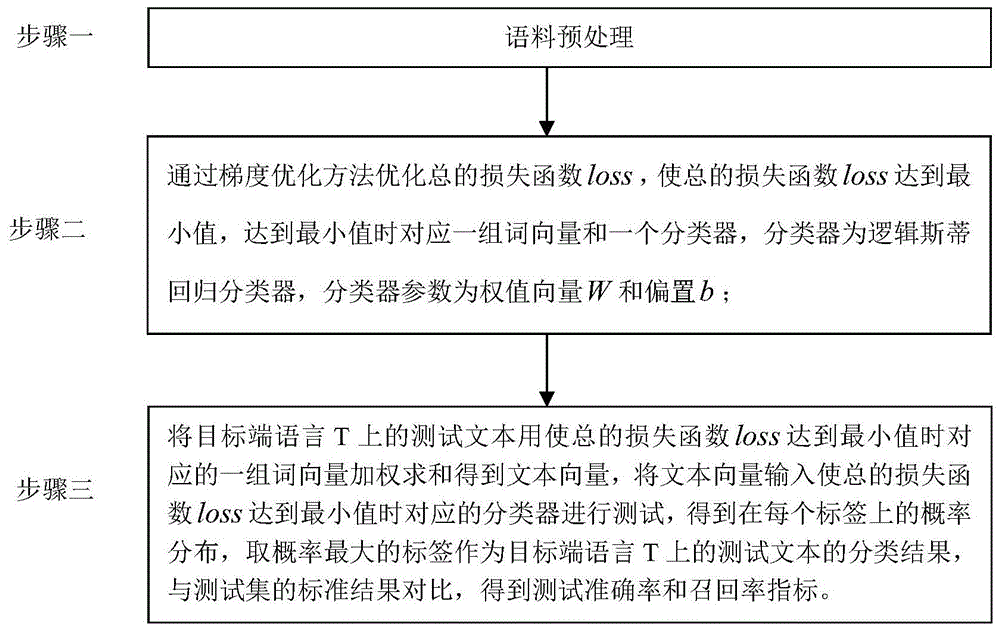
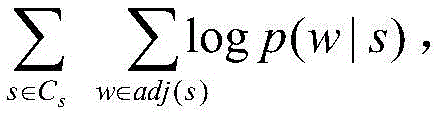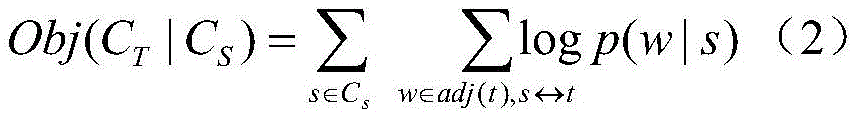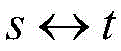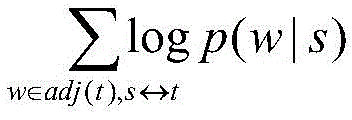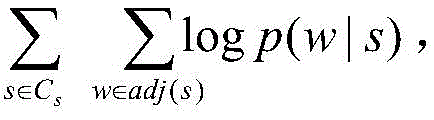Disclosure of Invention
The invention aims to solve the problems that the existing method based on synonym replacement has low classification accuracy, the existing method based on translation has high accuracy, but a large amount of linguistic data is needed for training a translator, the training time is long, and the complexity and the time consumption of a task far exceed those of a simple task of text classification, so that the method is not practical, and provides a cross-language text classification method based on cross-language word vector representation and classifier combined training.
The cross-language text classification method based on the cross-language word vector representation and the classifier joint training is characterized in that:
the method comprises the following steps: preprocessing the corpus:
extracting a word list from the parallel linguistic data, initializing a word vector matrix in the parallel linguistic data by adopting a random number between-0.1 and 0.1, and carrying out word stem reduction on the classified linguistic data to remove low-frequency word processing;
the parallel corpora are N pairs of English and corresponding Chinese translation;
the word list is all words in the parallel corpus, and each word has an index;
the word vector matrix is a word vector matrix formed by all word vectors in the parallel corpus;
english is used as a source end language and is set as S, the language of the text to be classified is used as a target end language and is set as T;
definition CsRepresenting the source language part, C, in parallel corporaTRepresenting a target end language part in the parallel corpus;
defining that a source end language S has | S | words, a target end language T has | T | words, and S and T respectively represent words of the source end language and the target end language;
step two: optimizing a total loss function loss (the calculation mode of the loss is given by a formula (7)) by a gradient optimization method (such as methods of SGD, Adam, AdaGrad and the like), so that the total loss function loss reaches a minimum value, and corresponds to a group of word vectors and a classifier when the total loss function loss reaches the minimum value, wherein the classifier is a logistic regression classifier, and parameters of the classifier are a weight vector W and an offset b;
step three: weighting and summing the test text on the target end language T by using a group of corresponding word vectors when the total loss function loss reaches the minimum value to obtain a text vector, inputting the text vector into a corresponding classifier when the total loss function loss reaches the minimum value to test to obtain probability distribution on each label, taking the label with the maximum probability as a classification result of the test text on the target end language T, and comparing the classification result with a standard result of a test set to obtain a test accuracy index and a recall rate index.
The invention has the beneficial effects that:
1. the method adopts the cross-language word vector as the representation of the text, obtains the cross-language word vector fused with the multilingual characteristics through the cross-language task training, and applies the cross-language word vector to the classification task, so that the text classification accuracy is high.
2. The invention breaks through the limitation of single training word vector of the existing method, unifies the training word vector and the optimization classifier in the same process, and performs combined training on word vector representation and the classifier, so that the word vector obtained by training not only contains cross-language information including source end language information and target end language information, but also integrates text category information, a large amount of linguistic data is not needed for training the translator, the training time is short, the practicability is strong, and the performance of the translator on a text classification task is better than that of the existing method.
The method and the device have a promoting effect on the fields of cross-language text processing, information retrieval, rare languages and the like. The invention has the innovation point that the limitation of the original method is broken through, the optimized word vector and the optimized classifier are unified in the same process, and the word vector representation and the classifier are trained in a combined manner, so that the obtained word vector has more excellent performance under a text classification task. The accuracy rate in the news classification task of the RCV road agency reaches over 90 percent and exceeds the existing method by about 2 percent. And meanwhile, good performance is obtained in the TED multi-language text classification task, and the method is well performed on 12 source end-target end language pairs.
Detailed Description
The first embodiment is as follows: the present embodiment is described with reference to fig. 1, and the specific process of the cross-language text classification method based on cross-language word vector representation and classifier joint training in the present embodiment is as follows:
the traditional text classification task usually represents words as a one-hot vector, represents texts as a high-dimensional text vector through a bag-of-words model, the dimension of the vector is consistent with the size of a word list, the component of the vector in each dimension represents the weight of a certain word in the texts, and the common useful word frequency represents the weight or 0 and 1 respectively represent the existence or nonexistence of the word. The bag-of-words representation causes serious sparseness and dimension problems. More computing resources are required to be consumed in larger-scale text classification. In addition, the bag of words indicates that context information and word order information of the words are ignored and the semantics cannot be expressed sufficiently.
The presence of word vectors solves this problem. Word vectors (also translated as word embedding, collectively referred to herein as word vectors) represent words as dense vectors of lower dimensions, typically obtained by training neural network language models. For example, word2vec is a more popular implementation of a single-word vector.
A cross-language word vector is a word vector that is capable of representing multi-lingual information. In the present invention, cross-language word vectors are employed as representations of words and thus constitute representations of text.
In order to establish a cross-language text classifier, a joint training method is provided for training a cross-language word vector fused with text category information, and then a text classifier is established in the vector space, wherein the text vector used by the text classifier is obtained by averaging the word vectors obtained by training.
English is used as a source language and is set as S, and the language of the text to be classified is set as a target language and is set as T. In the whole training process, the used corpus resources comprise: the source language text with class labels (the source language text for training), the parallel corpus are S and T languages without class labels, and the translation dictionary pairs of the S language and the T language, namely bilingual word alignment tables. The method does not use any labeled target end language text to participate in the training process, and is only used when the test indexes such as accuracy are calculated in the test stage.
In the whole training process, obtaining the cross-language word vector with the text category information through the joint training is the most key step. Formally, we define | S | words in the source language S and | T | words in the target language S and S and T denote words in the source and target languages, respectively, S and TIn parallel corpus, CsRepresenting a source language part, CTRepresenting a target end language portion. Word alignment information is also needed in our model, which can be automatically obtained from parallel corpora (via IBM model or other word alignment tools such as GIZA + +). Cross-language word vectors are trained by building a bilingual model. In bilingual models, each word s needs to predict the probability of its neighboring words in the corpus (equations 1 and 2) and the probability of neighboring words of the aligned word T in T (equations 3 and 4).
The method comprises the following steps: preprocessing the corpus:
extracting word lists from parallel linguistic data (each word list has a plurality of words, the parallel linguistic data comprises S and T), initializing word vector matrixes in the parallel linguistic data by adopting random numbers between-0.1 and 0.1, carrying out word stem reduction on classified linguistic data (the existing linguistic data with category labels, such as whether each section or each text is negative or positive, and whether the text is positive or negative or is 2 category labels), removing low-frequency words and the like;
the parallel corpora are N pairs of English and corresponding Chinese translation;
the word list is all words in the parallel corpus, and each word has an index (sequence number, several rows and several columns in the matrix);
the word vector matrix is a word vector matrix formed by all word vectors (each word is a word vector) in the parallel corpus;
english is used as a source language and is set as S, the language of a text to be classified (a text without a class label) is used as a target language and is set as T;
definition CsRepresenting the source language part, C, in parallel corporaTRepresenting a target end language part in the parallel corpus; the source language refers to a language, and the source language part in the parallel corpus refers to a part of the corpus belonging to the language. So that it is additionally indicated by one letter. Subscript indicates the language and C indicates that it is in the corpus.
Defining that a source end language S has | S | words, a target end language T has | T | words, and S and T respectively represent words of the source end language and the target end language;
step two: optimizing a total loss function loss by a gradient optimization method (such as SGD, Adam, AdaGrad and other methods), so that the total loss function loss reaches a minimum value, and corresponds to a group of word vectors and a classifier when the total loss function loss reaches the minimum value, wherein the classifier is a logistic regression classifier, and parameters of the classifier are a weight vector W and an offset b;
the training process of the second step is simply equivalent to:
1. initializing word vectors and classifier parameters w, b
2. Calculating loss by using word vectors, w and b in initialized word vectors
3. Updating the word vector, w, b such that loss is reduced
4. Repeating the step 3 to obtain final word vector and w, b
Therefore, although the optimization in the second step is loss, the updated word vector and w, b are finally obtained;
step three: the total loss function loss (the calculation mode of the loss function is shown by a formula (7)) is adopted, a corresponding classifier tests the test corpus (the existing test corpus is not provided with a label and has a category, and the test corpus is a target end), a test text on a target end language T is weighted and summed by a group of word vectors corresponding to the minimum loss function loss to obtain a text vector (the text vector is not provided with a label but has a plurality of categories),
and inputting the text vector into a corresponding classifier when the total loss function loss reaches the minimum value, testing to obtain the probability distribution on each label, taking the label with the maximum probability as the classification result of the test text on the target end language T, and comparing the classification result with the standard result (with the label and the category) of the test set to obtain indexes such as test accuracy, recall rate and the like.
The second embodiment is as follows: the first difference between the present embodiment and the specific embodiment is: the concrete solving process of the total loss function loss in the step two is as follows:
the overall loss function includes three terms:
one is the loss of the source language, namely the loss of the source language S, which is obtained from the source language part in the parallel corpus;
secondly, the loss of the target end language, namely the loss on the target end language T is obtained from the target end language part in the parallel linguistic data;
thirdly, classifier loss;
and constructing a total loss function loss according to the language loss of the source end, the language loss of the target end and the classifier loss.
Other steps and parameters are the same as those in the first embodiment.
The third concrete implementation mode: the present embodiment differs from the first or second embodiment in that: the source language loss, namely the loss on the source language S, is obtained from a source language part in the parallel corpus; the specific process is as follows:
at CsChinese, monolingual (using only C)s) The loss is:
wherein, CsRepresenting a source language part; obj (C)s|Cs) Representing monolingual loss in source language in parallel corpus; w represents one of the words in the context of the word s of the source language; p (w | s) represents the probability of predicting the window of s under the condition that the central word is s; adj(s) words that represent the context of the words s of the source language;
the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network; the process is as follows:
c is to besThe dimension 512 of the word vector is changed into | S | dimension after passing through a full connection layer, and after softmax operation, the probability operation expression of each word in the softmax operation is as follows:
wherein p is
iRepresenting the probability of the ith word, e
iRepresenting vectors generated after passing through fully-connected layersI dimension of (e)
jRepresenting the jth dimension of a vector generated after passing through the full connection layer, i is more than or equal to 1 and less than or equal to S, j is more than or equal to 1 and less than or equal to S, obtaining the probability of each word in S through softmax operation, picking out the probability represented by adj (S) from S, taking the logarithm and summing to obtain the probability
Obtained for each core word
Then adding to obtain
Outputting;
at CsIn, bilingual loss is:
wherein, CTRepresenting a target-side language portion; obj (C)T|CS) Representing bilingual loss in a source end language and a target end language in the parallel corpus; adj (t) words that represent the context of the word t in the target end language;
wherein
Representing aligned word pairs (one source-language word corresponds to one target-language word), the word alignment information being automatically obtained from parallel corpora (by IBM model or other word alignment tools such as GIZA + +); adj (.) represents a word adjacent to a certain word, and the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network;
the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network; the process is as follows:
c is to be
sThe word vectors of all words in the T are used as central word and word vectors and input into a neural network, the dimension 512 of the word vector is changed into | T | dimension after passing through a full connection layer, the probability of each word in the T is obtained through softmax operation, and the word vectors are picked out from the Tw∈adj(t),
The probabilities represented are summed up logarithmically to obtain
Obtained for each core word
Then adding to obtain
Other steps and parameters are the same as those in the first or second embodiment.
The fourth concrete implementation mode: the difference between this embodiment mode and one of the first to third embodiment modes is: the target end language loss, namely the loss on the target end language T, is obtained from the target end part in the parallel linguistic data; the specific process is as follows:
at CTIn, monolingual loss is:
Obj(CT|CT) Representing monolingual loss in a target end language in the parallel corpus;
the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network; the process is as follows:
c is to be
TThe word vectors of all words in the T are used as central word and word vectors and input into a neural network, the dimension 512 of the word vector is changed into | T | dimension after passing through a full connection layer, the probability of each word in the T is obtained through softmax operation, and the word vectors are picked out from the T
adj(t)The probabilities represented are summed up logarithmically to obtain
Obtained for each core word
Then adding to obtain
At CTIn, bilingual loss is:
Obj(C
S|C
T) Representing bilingual loss in a source end language and a target end language in the parallel corpus; wherein
Representing aligned word pairs (one target end language word corresponds to one source end language word), the word alignment information is automatically obtained from parallel corpora (by IBM model or other word alignment tools such as GIZA + +); adj (.) represents a word adjacent to a certain word, and the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network;
the probability value p in the formula is obtained by a double-layer fully-connected feedforward neural network; the process is as follows:
c is to be
TThe word vectors of all words in the S are used as central word and word vectors and input into a neural network, the dimension 512 of the word vector is changed into the dimension of | S | after passing through a full connection layer, the probability of each word in the S is obtained through softmax operation, w is belonged to adj (S) from the S,
the probabilities represented are summed up logarithmically to obtain
Obtained for each core word
Then adding to obtain
Combining (1), (2), (3) and (4) to obtain an objective function on the parallel corpus:
Obj(C)=α1Obj(CS|CS)+α2Obj(CT|CS)+α3Obj(CT|CT)+α4Obj(CS|CT),(5)
wherein alpha is1,α2,α3,α4The hyper-parameters are scalar quantities.
Other steps and parameters are the same as those in one of the first to third embodiments.
The fifth concrete implementation mode: the difference between this embodiment and one of the first to fourth embodiments is: the classifier penalty is:
since the task is to train the text classifier, the ideal word vector needs to carry text category information. Therefore, text category information needs to be fused into the word vectors, the way is that linguistic data of text classification is used as supervision information in the training process, the loss of a text classifier is added into a loss function, and a bilingual model and the text classifier are subjected to combined training to obtain the word vectors which are fused with text label information and cross-language information.
A logistic regression classifier is adopted as a text classifier, and the loss of the text classifier adopts a cross entropy loss function and is recorded as L; the text classifier penalty function is:
wherein, C
LRepresenting text classification corpora (tagged), S
dRepresenting any text in the text classification corpus; x represents a text vector and is obtained by weighted summation of word vectors of each word in the text; x
SdAs a text S
dA representative text vector, b is an offset; w is a weight vector corresponding to each text category (2W for the second category and 4W for the fourth category), tag (S)
d) As a text S
dThe tag of (positive or negative),
as a text S
dThe weight vector corresponding to the label of (1).
Other steps and parameters are the same as in one of the first to fourth embodiments.
The sixth specific implementation mode: the difference between this embodiment and one of the first to fifth embodiments is: obtaining a total loss function according to the source end language loss, the target end language loss and the classifier loss; the concrete formula is as follows:
loss=-Obj(C)-L(CL) (7)
wherein obj (C) represents an objective function on the parallel corpus; l (C)L) Representing a text classifier loss function;
after a classifier loss function is added, the word vector information obtained by training is fused with monolingual information, cross-language information and text category information, and can meet the task requirements of people.
Other steps and parameters are the same as those in one of the first to fifth embodiments.
The seventh embodiment: the difference between this embodiment and one of the first to sixth embodiments is: in the second step, the total loss function loss is optimized by a gradient optimization method (such as SGD, Adam, AdaGrad and other methods) to make the total loss function loss reach a minimum value, and the specific process is as follows:
1) calculating partial derivatives of the total loss function loss to a word vector (each word represented by the parallel corpus from the first step) matrix, and calculating partial derivatives of the total loss function loss to a weight vector W and a bias b (in formula 6);
2) subtracting a partial derivative of the loss to the current word vector matrix from the value of the current word vector matrix, subtracting a partial derivative of the loss to the current weight vector W from the current weight vector W, and subtracting a partial derivative of the loss to the current bias b from the current bias b to calculate a total loss function loss;
3) and (3) repeatedly executing the steps 1) and 2) until the partial derivative of the step 1) is zero or loss is not reduced (the partial derivative and the loss are 1), and obtaining a corresponding group of word vectors and a classifier at the moment, wherein the classifier is a logistic regression classifier, and the classifier parameters are a weight vector W and an offset b.
Other steps and parameters are the same as those in one of the first to sixth embodiments.
The following examples were used to demonstrate the beneficial effects of the present invention:
the first embodiment is as follows:
the preparation method comprises the following steps:
the method comprises the following steps: preprocessing the corpus: including extracting a vocabulary and initializing a word vector matrix. Parallel corpora of the European parliament (100 ten thousand sentences per language pair) are adopted as the parallel corpora required by training word vectors, text classification training is carried out by adopting TED corpora, and the data set is a binary classification task. And performing word stem reduction on the classified linguistic data, removing low-frequency words and the like. The scheme also needs bilingual word alignment resources, if the bilingual word alignment resources are lacked, a GIZA + + tool is needed, and a bilingual word alignment table is obtained by training bilingual parallel linguistic data.
Step two: a loss function is constructed. The loss function includes three items, one is the loss of the source language, i.e. the loss in the source language S, which is obtained from the source part of the parallel corpus. The calculation method is obtained from the target end part in the parallel corpus according to the formula (1) and the formula (2). the second formula is the target end loss, and the calculation method is shown in the formula (3) and the formula (4). The probability p in each formula is calculated by a two-layer feed neural network. And thirdly, classifier loss, which is obtained by the formula (6). The total loss function is calculated by equation (7).
Step three: and (5) training and testing. The loss function is constructed in a specific corpus, and training is performed by using a gradient-based optimization method (such as SGD, Adam, AdaGrad and other methods) and using a word vector matrix and classifier parameters on the whole word list as trainable parameters of the whole objective function until convergence. And then testing on the test corpus. And obtaining a test result. This example uses SGD (random gradient descent method) as the optimization method.
The test result shows that: the classification accuracy obtained on multiple language pairs on a TED dataset exceeds that of the existing methods, F on Ender language pairs1The value reached 0.413.
Example two:
the preparation method comprises the following steps:
the method comprises the following steps: preprocessing the corpus: including extracting a vocabulary and initializing a word vector matrix. The European parliament parallel corpus (100 ten thousand sentences per language pair) is used as the parallel corpus required by training word vectors, and RCV1 corpus is used for text classification training, and the data set is a four-classification task. And performing word stem reduction on the classified linguistic data, removing low-frequency words and the like. And a bilingual word alignment table, namely a translation dictionary, is obtained by utilizing parallel corpus training through a GIZA + + tool.
Step two: a loss function is constructed. A loss function is constructed. The loss function includes three items, one is the loss of the source language, i.e. the loss of the source language S, which is obtained from the source part of the parallel corpus. The calculation method is obtained from the target end part in the parallel corpus according to the formula (1) and the formula (2). the second formula is the target end loss, and the calculation method is shown in the formula (3) and the formula (4). The probability p in each formula is calculated by a two-layer feed neural network. And thirdly, classifier loss is obtained by a multi-classification logistic regression loss function improved by the formula (6), namely a cross entropy loss function of softmax regression. The expression of the loss function is:
the total loss function is obtained by the formula (7), wherein the loss part of the multi-classification classifier needs to be improved from the formula (6) to the formula (8).
Step three: and (5) training and testing. The loss function is constructed in a specific corpus, and training is performed by using a gradient-based optimization method (such as SGD, Adam, AdaGrad and other methods) and using a word vector matrix and classifier parameters on the whole word list as trainable parameters of the whole objective function until convergence. And then testing on the test corpus. And obtaining a test result. This example uses the Adam method as the optimization method.
The test result shows that: the classification accuracy rate obtained by the method on the RCV corpus exceeds the existing scheme. The correctness of the classification result obtained on the English language pair is 90.2%.
The present invention is capable of other embodiments and its several details are capable of modifications in various obvious respects, all without departing from the spirit and scope of the present invention.