US9779085B2 - Multilingual embeddings for natural language processing - Google Patents
Multilingual embeddings for natural language processing Download PDFInfo
- Publication number
- US9779085B2 US9779085B2 US14/863,996 US201514863996A US9779085B2 US 9779085 B2 US9779085 B2 US 9779085B2 US 201514863996 A US201514863996 A US 201514863996A US 9779085 B2 US9779085 B2 US 9779085B2
- Authority
- US
- United States
- Prior art keywords
- multilingual
- embedding
- word
- training data
- languages
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active, expires
Links
Images








Classifications
-
- G06F17/2818—
-
- G06F17/2735—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/44—Statistical methods, e.g. probability models
Definitions
- One embodiment is directed generally to a computer system, and in particular to a computer system that performs natural language processing tasks.
- NLP natural language processing
- One embodiment is a system that manages NLP model training.
- An unlabeled corpus of multilingual documents is provided that span a plurality of target languages.
- the system trains a multilingual embedding on the corpus of multilingual documents as input training data.
- the system generalizes the multilingual embedding across the target languages by modifying the input training data and/or transforming multilingual dictionaries into constraints in an underlying optimization problem.
- the system trains an NLP model on training data for a first language of the target languages, using word embeddings of the trained multilingual embedding as features.
- the system applies the trained NLP model on data from a second of the target languages, the first and second languages being different.
- FIG. 1 is a block diagram of a computer system that can implement an embodiment of the present invention.
- FIG. 2A illustrates a word to context-word co-occurrence matrix for a bilingual corpus (English and French) of prior art systems.
- FIG. 2B illustrates a word to context-word co-occurrence matrix after artificial code-switching is applied, in accordance with an embodiment of the invention.
- FIG. 3 illustrates a flow diagram of the functionality of training a multilingual embedding for performing NLP tasks, in accordance with an embodiment of the invention.
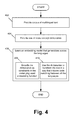
- FIG. 4 illustrates a flow diagram of the functionality of training a multilingual embedding that generalizes across languages, in accordance with an embodiment of the invention.
- FIG. 5 illustrates different updates on word-context pairs, in accordance with an embodiment of the invention.
- FIG. 6 illustrates a flow diagram of the functionality of training a multilingual embedding that generalizes across languages, in accordance with an embodiment of the invention.
- FIG. 7 is a table illustrating experimental data, in accordance with an embodiment of the invention.
- FIG. 8 is a table comparing different multilingual embeddings, in accordance with an embodiment of the invention.
- FIG. 9 is a table illustrating sentiment analysis results, in accordance with an embodiment of the invention.
- a system trains a natural language processing (“NLP”) model in one language and applies that NLP model to a different language.
- NLP natural language processing
- the system can use large collections of unlabeled multilingual data to find a common representation in which structure is shared across languages. Under such representations, the system can train an NLP model in a language with many resources and generalize that model to work on lower resource languages.
- multilingual word embeddings can substantially reduce the cost and effort required in developing cross-lingual NLP tools.
- FIG. 1 is a block diagram of a computer system 10 that can implement an embodiment of the present invention. Although shown as a single system, the functionality of system 10 can be implemented as a distributed system.
- System 10 includes a bus 12 or other communication mechanism for communicating information, and a processor 22 coupled to bus 12 for processing information.
- Processor 22 may be any type of general or specific purpose processor.
- System 10 further includes a memory 14 for storing information and instructions to be executed by processor 22 .
- Memory 14 can be comprised of any combination of random access memory (“RAM”), read only memory (“ROM”), static storage such as a magnetic or optical disk, or any other type of computer readable media.
- System 10 further includes a communication device 20 , such as a network interface card, to provide access to a network. Therefore, a user may interface with system 10 directly, or remotely through a network or any other method.
- a communication device 20 such as a network interface card
- Computer readable media may be any available media that can be accessed by processor 22 and includes both volatile and nonvolatile media, removable and non-removable media, and communication media.
- Communication media may include computer readable instructions, data structures, program modules or other data in a modulated data signal such as a carrier wave or other transport mechanism and includes any information delivery media.
- Processor 22 is further coupled via bus 12 to a display 24 , such as a Liquid Crystal Display (“LCD”), for displaying information to a user.
- a display 24 such as a Liquid Crystal Display (“LCD”)
- LCD Liquid Crystal Display
- a keyboard 26 and a cursor control device 28 is further coupled to bus 12 to enable a user to interface with system 10 .
- memory 14 stores software modules that provide functionality when executed by processor 22 .
- the modules include an operating system 15 that provides operating system functionality for system 10 .
- the modules further include an NLP manager 18 that optimizes/manages NLP model training, as disclosed in more detail below.
- the modules further include one or more functional modules 19 that can include the additional functionality, such as modules for performing NLP tasks such as automatic summarization, coreference resolution, discourse analysis, machine translation, morphological segmentation, named entity recognition (“NER”), natural language generation, natural language understanding, optical character recognition (“OCR”), part-of-speech tagging, parsing, question answering, relationship extraction, sentence breaking (or sentence boundary disambiguation), sentiment analysis, speech recognition, speech segmentation, topic segmentation and recognition, word segmentation, word sense disambiguation, information retrieval (“IR”), information extraction (“IE”), speech processing (speech recognition, text-to-speech and related tasks), native language identification, stemming, text simplification, text-to-speech, text-proofing, natural language search,
- a database 17 is coupled to bus 12 to provide centralized storage for modules 18 and 19 .
- Database 17 can store data in an integrated collection of logically-related records or files.
- Database 17 can be an operational database, an analytical database, a data warehouse, a distributed database, an end-user database, an external database, a navigational database, an in-memory database, a document-oriented database, a real-time database, a relational database, an object-oriented database, or any other database known in the art.
- system 10 is configured to train an NLP model in one language and apply that NLP model to a different language.
- System 10 can use large collections of unlabeled multilingual data to find a common representation in which structure is shared across languages. Under such representations, system 10 can train an NLP model in a language with many resources and generalize that model to work on lower resource languages.
- multilingual word embeddings can substantially reduce the cost and effort required in developing cross-lingual NLP tools.
- Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing where words from the vocabulary (and possibly phrases thereof) are mapped to vectors of real numbers in a low dimensional space, relative to the vocabulary size (“continuous space”). Word embeddings map word-types to dense, low dimensional (e.g., 300) vectors, and are advantageous for NLP because they help cope with the sparsity problems associated with text. Using embeddings learned from monolingual text as features improves the accuracy of existing NLP models.
- FIG. 2A illustrates a word to context-word co-occurrence matrix 202 for a bilingual corpus (English and French) of prior art systems.
- Visualizing the word to context-word co-occurrence statistics as matrix 202 reveals large blocks of connectivity for each language, with sparse scattering of non-zero cells elsewhere. This block structure causes problems as many word embedding techniques can be seen as performing matrix factorization on co-occurrence matrices.
- Embodiments can perform one or both of two approaches for improving multilingual embeddings via human provided dictionaries that translate a small subset of vocabulary words across multiple languages.
- the underlying embedding method is augmented with a set of constraints derived from the word translations. The constraints force dictionary words to have similar magnitudes and angles between them.
- the data is transformed using a process termed artificial code switching (“ACS”). This process employs the translation dictionaries to replace some of the words in the text with words from another language.
- ACS artificial code switching
- FIG. 2B illustrates a word to context-word co-occurrence matrix 204 after artificial code-switching is applied, in accordance with an embodiment of the invention.
- Matrix 202 shown in FIG. 2A is essentially block diagonal, but each block is fairly sparse as it represents the co-occurrence of words within the language. Effectively, the artificial code switching approach fills in more cells of co-occurrence matrix 204 making matrix 204 less block diagonal than bilingual co-occurrence matrix 202 , and thus ripe for learning multilingual representations.
- Embodiments improve the quality of multilingual embeddings over a system that relies upon natural cross lingual co-occurrences alone. Further, multilingual word analogy data demonstrates that combining multiple languages into a single space enables lower resource languages to benefit from the massive amount of data available in higher resource languages. It has been determined that ACS in particular learns the best multilingual word embeddings, achieving more than 50% accuracy on bilingual word analogies.
- the multilingual embeddings disclosed herein allow for embodiments to build sentiment models in languages without training data by training models on, for example, English, and using the embedding to generalize the information to other languages.
- system 10 can consume a large corpus of multilingual text and produce a single, unified word embedding in which the word vectors generalize across languages.
- System 10 is agnostic about the languages with which the documents in the corpus are expressed, and does not rely, as with known systems, on parallel corpora to constrain the spaces.
- Parallel corpora are large collections of parallel texts, each parallel text being a text placed alongside its translation or translations.
- Parallel corpora may be aligned at the sentence level which is a non-trivial task. For many languages, it may be difficult and/or too costly to acquire large parallel corpora. Instead, system 10 utilizes a small set of human provided word translations via one or both of two approaches.
- the first approach transforms these multilingual dictionaries into constraints in the underlying optimization problem.
- the second approach more directly exploits the distributional hypothesis via artificial code switching.
- system 10 can induce code-switching so that words across multiple languages appear in contexts together.
- the models learn common cross-lingual structure, the common structure allows an NLP model trained in one language to be applied to another and achieve up to 80% of the accuracy of models trained on in-language data.
- system 10 combines many corpora from many languages into the same embedding space.
- System 10 can combine all such corpora into a single embedding space, and use this one embedding space to provide the features for all of the languages.
- System 10 can use a limited number of translated word pairs which can be extracted from dictionaries.
- FIG. 3 illustrates a flow diagram of the functionality of training a multilingual embedding for performing NLP tasks, in accordance with an embodiment of the invention.
- each functionality may be performed by hardware (e.g., through the use of an application specific integrated circuit (“ASIC”), a programmable gate array (“PGA”), a field programmable gate array (“FPGA”), etc.), or any combination of hardware and software.
- ASIC application specific integrated circuit
- PGA programmable gate array
- FPGA field programmable gate array
- a multilingual embedding is trained on a large, unlabeled corpus of multilingual documents that span the desired languages.
- the multilingual embedding can be trained as described, for example, by FIG. 4 discussed below.
- the multilingual embedding can be generalized across languages by modifying input training data (e.g., via artificial code switching) and/or modification of the training algorithm step (e.g., by transforming multilingual dictionaries into constraints in the underlying optimization problem).
- an NLP model is trained on all available training data, using word embeddings as features.
- the trained model is applied on data from any of the target languages to achieve accuracy comparable to having in-language training data.
- FIG. 4 illustrates a flow diagram of the functionality of training a multilingual embedding that generalizes across languages, in accordance with an embodiment of the invention. It has been shown that models such as continuous bag-of-words (“CBOW”) capture a large amount of the syntactic/semantic structure of a language. Embodiments extend these models so as to generalize such structure across multiple languages using one or both of two approaches: augmenting the objective function with multilingual constraints, and/or transforming the input data to produce multilingual contexts.
- CBOW continuous bag-of-words
- V m the vocabulary of all the languages.
- a large corpus of multilingual text can be provided with documents D i ⁇ comprised of word sequences w 1 , . . . , w n i where each w j ⁇ V.
- the large corpus can comprise a large number of documents from websites such as Wikipedia (http://www.wikipedia.com), blogs, newswire, Twitter (http://www.twitter.com), and other social media that contain documents in multiple languages.
- a concept dictionary is a set of concepts where each concept C i ⁇ is a set of words that all have similar meaning (e.g., a concept set containing “red”, “rouge” and “rojo”). Note that the language for any given word or document is not necessarily known.
- an embedding model V ⁇ k is learned that maps each word type to a k-dimensional vector such that the vectors capture syntactic and semantic relations between words in a way that generalizes across the languages.
- Embodiments generate a solution space that is modular in the sense that the multilingual approaches are compatible with many underlying (monolingual) embedding methods. In this way, it is easy to implement the techniques on top of existing embedding implementations such as Latent Semantic Analysis (“LSA”), Restricted Boltzmann Machines (“RBMs”), CBOW, skip-grams (or “SkipGram”), Global Vectors for Word Representation (“GloVe”), or Latent Dirichlet Allocation (“LDA”).
- LSA Latent Semantic Analysis
- RBMs Restricted Boltzmann Machines
- CBOW skip-grams
- GloVe Global Vectors for Word Representation
- LDA Latent Dirichlet Allocation
- Equation 1 argmax W ⁇ ( ; W ) (1)
- ⁇ ⁇ ( x ) 1 1 + e - x is the sigmoid function, is the negative dataset and V is the output weights.
- the context is a single word, whereas in CBOW it is the average vector over the context window.
- Embodiments can perform one or both of two approaches 408 / 410 of FIG. 4 when learning multilingual embeddings at 406 .
- the dictionaries are directly encoded as constraints in the underlying word embedding objective function.
- concept-based constraints There are many possible ways to impose concept-based constraints on the underlying model. Two possibilities are as follows.
- the challenge is developing a function g that both respects the data and structure of the language while also encouraging common structure to be shared between words in different languages that have similar meanings.
- g( ; W) can be set to increase the probability of a word being in its concept sets.
- word vectors would be learned that jointly predict their context and also predict the concept sets to which they belong as follows (“Equation 3”):
- g ( ; W ) p ( w ⁇ c; W ) (3)
- (w) ⁇ c
- c ⁇ w ⁇ c ⁇ are concepts containing w
- the dictionaries are used to transform the data in a way that induces code switching between all the languages.
- Code-switching is the process in which a speaker of multiple languages switches between those languages in discourse. Code-switching overlaps the meaning between two (or more) languages, and so the distributional representation of a word in one language is linked to context words from another language. Thus the result of code-switching provides rich multilingual context for training window based word embeddings.
- code-switching is an infrequent event.
- one approach would be to use a classifier to identify instances of code-switching and treat such contexts in a special way (e.g., by giving higher weight to the updates from the code-switched data).
- the problem of language identification is non-trivial. Also it is not clear that sufficient natural code-switching occurs in large datasets such as Wikipedia.
- the dictionaries can be used to artificially induce extra code-switching in the input data.
- This process termed Artificial Code-Switching (“ACS”), fills in unobserved cells in the word to context-word co-occurrence matrix, as shown, for example, in FIG. 2 and discussed above.
- ACS Artificial Code-Switching
- This extra knowledge is analogous to having extra recommendations in a recommender system (i.e., recommendations that a word in one language could be substituted for a word in another language).
- One question is how to fill the cells of this matrix in a way that most naturally causes the learning of shared structure in the multilingual space.
- One way of accomplishing this is to fill in the matrix by randomly replacing a word in one language with its translation in another. In this way, co-occurrence “mass” from the monolingual blocks is shared across languages.
- FIG. 5 illustrates different updates on word-context pairs, in accordance with an embodiment of the invention.
- FIG. 5 shows different kinds of updates that can be performed on a multilingual set of words and contexts.
- Constraint updates discussed above at 408 of FIG. 4 are illustrated as a dotted line 502 , representing the constraints pulling the vectors for “rouge” and “red” closer together. As these two words are pulled together the context words also move closer.
- the CBOW update is shown as an unbroken black arrow 506 .
- the update performed by CBOW moves the context closer to the word, and the word closer to the context.
- the code-switching update 504 moves the English word “red” closer to the French context for the word “rouge” and vice versa. This does not directly affect the relationship between “red” and “rouge” but over repeated updates it enforces a relaxed form of the constraint update.
- FIG. 6 illustrates a flow diagram of the functionality of training a multilingual embedding that generalizes across languages, in accordance with an embodiment of the invention.
- the text is tokenized into stream of words.
- the code switched language data is interleaved as input to a training algorithm for learning a multilingual embedding. For example, a line of text from an English document can be provided as input to the training algorithm followed by a line of text from a French document.
- a lookup for other words is performed in the dictionary based on the current update and the other words are updated such that the angles between the current and the other words are close to each other. For example, constraints can be used to force the current and other dictionary words to have similar magnitudes and angles between them.
- in-language training data is provided in a first language for an NLP task (e.g., sentiment analysis).
- words in the in-language training data are replaced with high-dimensional vectors from the multilingual embedding.
- an NLP model is trained by preforming a classification process which learns the relationship between a place in the vector space and positive/negative/neutral sentiment.
- sentiment of text in a second language is detected using the NLP model trained using in-language training data of the first language.
- 606 artificial code switching
- 610 predicted constraints
- FIG. 7 is a table 700 illustrating experimental data, in accordance with an embodiment of the invention.
- the experiments are used to assess the quality and practicality of the multilingual embedding spaces.
- the first set of experiments measures the former, and the second set measure the latter on the task of sentiment analysis.
- Five languages were selected to represent various levels of resource-availability, as reflected by the number of Wikipedia pages. English has almost five million pages in Wikipedia, French, German and Spanish each have over a million, whereas, Bokm ⁇ l has over 100,000 articles.
- Table 700 includes a list of the languages. Languages with even fewer Wikipedia pages were considered, but a large proportion of the pages were found to be stubs, and hence less useful.
- Each system employs CBOW as the underlying model ⁇ .
- the multilingual embedding models also employ a set of human provided concept dictionaries that translate words with similar meaning from one language to another. Such dictionaries are readily available, and for the purpose of these experiments OmegaWiki was used, a community based effort to provide definitions and translations for every language in the world.
- Systems include:
- the data in experiments comprises interleaved documents from the various mono-lingual Wikipedias: bilingual experiments involve Wikipedia documents in two languages, and multilingual experiments use Wikipedia documents from all five languages. In all experiments, the same CBOW parameters are used (two iterations, 300 dimensions, initial learning rate 0.05, filter words occurring fewer than 10 times).
- FIG. 8 is a table 800 comparing different multilingual embeddings, in accordance with an embodiment of the invention.
- the quality of the joint multilingual embedding space is evaluated. Two aspects of the spaces have been assessed. First, the amount of structure shared across languages. Second, as the number of languages increases in the shared space, how does the quality of the individual language's representation change in this space.
- a mixed bilingual (En+Fr) analogy tasks by mixing words from the monolingual analogies, e.g., Appel:roi:: woman:queen.
- the OmegaWiki are split concepts into 50/50 training/testing sets.
- the embedding models can be trained using half the concepts, and other half can be used for evaluating the quality of the embedding (via the average cosine similarity of words that appear in the same concept).
- FIG. 9 is a table 900 illustrating sentiment analysis results, in accordance with an embodiment of the invention.
- This experiment tests if multilingual embeddings allow an NLP model to be trained on a high resource language (English), and then evaluate it on languages for which no training data exists.
- a high resource language English
- a document-level sentiment analysis the task of classifying a document as expressing overall positive, negative or neutral sentiment was evaluated.
- the success of multilingual embeddings hinges upon whether the sentiment information captured in the word embedding dimensions generalizes across languages.
- Sentiment data was labelled (three classes) for the five languages: English, Spanish, French, German and Bokm ⁇ l.
- the data comprises various sources such as product reviews, social media streams, and the micro-blogging site, Twitter.
- sentiment classifiers are trained on each of the target language's training data, using unigrams, bigrams, and bias, but no embeddings as features (termed “target language baselines”).
- target language baselines are established by training the lexical-based classifier on English.
- cross-lingual models are trained on English using only multilingual (all five languages) word embeddings as features (i.e., no lexical and bias features) by averaging the normalized word vectors in each document.
- the cross-lingual embedding models are trained on French to evaluate English as a target language. Spanish, German and Bokmal were also trained on and the results were similar.
- Table 900 The results are presented in Table 900 .
- the rows are grouped according to the test language, and in each group, the target language baseline is separated from the cross-lingual models via a dotted line. Accuracy is reported on both the complete data (columns prefixed with “To”), as well as the subset derived from Twitter (columns prefixed with “Tw”).
- the Twitter experiments use Twitter training data exclusively. In each of these languages (except Bokm ⁇ l), the distribution of positive, negative and neutral class is well balanced, and hence comparable patterns are seen when evaluating with accuracy or F 1 .
- the fraction of accuracy achieved is also reported with respect to the target language baseline (columns suffixed with “AFrac”). In other words, this is asking, “what fraction of accuracy is obtained by using only source training data instead of target language training data.”
- the first two columns 902 and 904 in both bilingual and multilingual sections of the table represent fraction of the target language baseline accuracy for Twitter and complete datasets, respectively.
- source-trained models achieve a high fraction of the accuracy of the “in target baseline” without using target training data.
- the fraction is especially high, often over 80%. This is due to the fact that the short tweets have a high information content per word, and sentiment bearing words contribute more weight to embedding-dimension features.
- embodiments can perform one or both of two methods for training multilingual word embedding models that integrate multiple languages into a shared vector space. These methods can operate using only a small dictionary of translated words to align the vector spaces, allowing useful inferences to be made across languages, based solely upon the vectors.
- the constraint approach introduces links between the words themselves, and the artificial code switching gives a softer link between a word and a context in a different language. Both of these approaches allow for generalizing a model trained on one language, and recover much of the test performance in another language.
- Embodiments can thereby learn a common representation across multiple languages so a model can be trained in a first language for which high resources are available (e.g., English) and then the model can be applied to all the other different languages without having to gather resources for those languages.
- An embedding model can contain more than two languages, and that these multilingual models can outperform bilingual models.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
Abstract
Description
is the sigmoid function,
ƒ′(
Where g(
g(
Where
g(
-
- Monolingual—A baseline system in which separate embeddings are trained for each language on monolingual data with CBOW.
- CBOW No constraints (no const)—A baseline system in which we train CBOW on a multilingual corpus.
- CBOW With constraints (with const)—The method described by setting g to Equation 4. After each CBOW update, updates are performed to satisfy g on words in the context for which there is a constraint.
- Artificial code switching (ACS)—The artificial code switching approach described above in which the concept sets in OmegaWiki are used to perform the word substitutions. The parameter α=0.25. (α=0.25 is an initial guess for the parameter based; it was found on development data that the method is robust to the setting of α.)
Claims (20)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/863,996 US9779085B2 (en) | 2015-05-29 | 2015-09-24 | Multilingual embeddings for natural language processing |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562168235P | 2015-05-29 | 2015-05-29 | |
| US14/863,996 US9779085B2 (en) | 2015-05-29 | 2015-09-24 | Multilingual embeddings for natural language processing |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20160350288A1 US20160350288A1 (en) | 2016-12-01 |
| US9779085B2 true US9779085B2 (en) | 2017-10-03 |
Family
ID=57397120
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/863,996 Active 2036-04-12 US9779085B2 (en) | 2015-05-29 | 2015-09-24 | Multilingual embeddings for natural language processing |
Country Status (1)
| Country | Link |
|---|---|
| US (1) | US9779085B2 (en) |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109299284A (en) * | 2018-08-31 | 2019-02-01 | 中国地质大学(武汉) | A Knowledge Graph Representation Learning Method Based on Structural Information and Text Description |
| CN109871529A (en) * | 2017-12-04 | 2019-06-11 | 三星电子株式会社 | Language processing method and apparatus |
| US10579733B2 (en) | 2018-05-10 | 2020-03-03 | Google Llc | Identifying codemixed text |
| US10769307B2 (en) | 2018-05-30 | 2020-09-08 | Bank Of America Corporation | Processing system using natural language processing for performing dataset filtering and sanitization |
| US10936635B2 (en) | 2018-10-08 | 2021-03-02 | International Business Machines Corporation | Context-based generation of semantically-similar phrases |
| US10997977B2 (en) * | 2019-04-30 | 2021-05-04 | Sap Se | Hybrid NLP scenarios for mobile devices |
| US11176327B2 (en) * | 2016-10-04 | 2021-11-16 | Fujitsu Limited | Information processing device, learning method, and storage medium |
| US11222176B2 (en) | 2019-05-24 | 2022-01-11 | International Business Machines Corporation | Method and system for language and domain acceleration with embedding evaluation |
| US11227120B2 (en) * | 2019-05-02 | 2022-01-18 | King Fahd University Of Petroleum And Minerals | Open domain targeted sentiment classification using semisupervised dynamic generation of feature attributes |
| US11341339B1 (en) * | 2020-05-14 | 2022-05-24 | Amazon Technologies, Inc. | Confidence calibration for natural-language understanding models that provides optimal interpretability |
| US11386276B2 (en) * | 2019-05-24 | 2022-07-12 | International Business Machines Corporation | Method and system for language and domain acceleration with embedding alignment |
| US11393456B1 (en) * | 2020-06-26 | 2022-07-19 | Amazon Technologies, Inc. | Spoken language understanding system |
| US11599768B2 (en) | 2019-07-18 | 2023-03-07 | International Business Machines Corporation | Cooperative neural network for recommending next user action |
| US11741318B2 (en) | 2021-03-25 | 2023-08-29 | Nec Corporation | Open information extraction from low resource languages |
| US11853712B2 (en) | 2021-06-07 | 2023-12-26 | International Business Machines Corporation | Conversational AI with multi-lingual human chatlogs |
| US11875131B2 (en) | 2020-09-16 | 2024-01-16 | International Business Machines Corporation | Zero-shot cross-lingual transfer learning |
Families Citing this family (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10162813B2 (en) | 2013-11-21 | 2018-12-25 | Microsoft Technology Licensing, Llc | Dialogue evaluation via multiple hypothesis ranking |
| US10339916B2 (en) * | 2015-08-31 | 2019-07-02 | Microsoft Technology Licensing, Llc | Generation and application of universal hypothesis ranking model |
| US10628522B2 (en) * | 2016-06-27 | 2020-04-21 | International Business Machines Corporation | Creating rules and dictionaries in a cyclical pattern matching process |
| JP6705318B2 (en) * | 2016-07-14 | 2020-06-03 | 富士通株式会社 | Bilingual dictionary creating apparatus, bilingual dictionary creating method, and bilingual dictionary creating program |
| KR102693666B1 (en) * | 2016-12-29 | 2024-08-09 | 주식회사 엔씨소프트 | Apparatus and method for detecting debatable document |
| US11151894B1 (en) * | 2017-02-02 | 2021-10-19 | Educational Testing Service | Systems and methods for scoring argument critique written essays |
| US20180232443A1 (en) * | 2017-02-16 | 2018-08-16 | Globality, Inc. | Intelligent matching system with ontology-aided relation extraction |
| EP3616083A4 (en) * | 2017-04-23 | 2021-01-13 | Nuance Communications, Inc. | Multi-lingual semantic parser based on transferred learning |
| US10380259B2 (en) * | 2017-05-22 | 2019-08-13 | International Business Machines Corporation | Deep embedding for natural language content based on semantic dependencies |
| US20190065486A1 (en) * | 2017-08-24 | 2019-02-28 | Microsoft Technology Licensing, Llc | Compression of word embeddings for natural language processing systems |
| CN107957989B9 (en) * | 2017-10-23 | 2021-01-12 | 创新先进技术有限公司 | Cluster-based word vector processing method, device and equipment |
| CN108170663A (en) | 2017-11-14 | 2018-06-15 | 阿里巴巴集团控股有限公司 | Term vector processing method, device and equipment based on cluster |
| CN110019304B (en) * | 2017-12-18 | 2024-01-05 | 上海智臻智能网络科技股份有限公司 | Method for expanding question-answering knowledge base, storage medium and terminal |
| US10657332B2 (en) * | 2017-12-21 | 2020-05-19 | Facebook, Inc. | Language-agnostic understanding |
| US10685358B2 (en) * | 2018-03-02 | 2020-06-16 | Capital One Services, Llc | Thoughtful gesture generation systems and methods |
| US11520992B2 (en) * | 2018-03-23 | 2022-12-06 | Servicenow, Inc. | Hybrid learning system for natural language understanding |
| KR102542914B1 (en) * | 2018-04-30 | 2023-06-15 | 삼성전자주식회사 | Multilingual translation device and multilingual translation method |
| CN108960317B (en) * | 2018-06-27 | 2021-09-28 | 哈尔滨工业大学 | Cross-language text classification method based on word vector representation and classifier combined training |
| CN112771564B (en) | 2018-07-18 | 2024-06-04 | 邓白氏公司 | Artificial intelligence engine for generating semantic directions of websites to automatically entity-find to-map identities |
| CN109213995B (en) * | 2018-08-02 | 2022-11-18 | 哈尔滨工程大学 | Cross-language text similarity evaluation technology based on bilingual word embedding |
| CN109271635B (en) * | 2018-09-18 | 2023-02-07 | 中山大学 | Word vector improvement method embedded in external dictionary information |
| CN109446537B (en) * | 2018-11-05 | 2022-11-25 | 安庆师范大学 | A translation evaluation method and device for machine translation |
| CN109670171B (en) * | 2018-11-23 | 2021-05-14 | 山西大学 | A word vector representation learning method based on asymmetric co-occurrence of word pairs |
| US11410031B2 (en) | 2018-11-29 | 2022-08-09 | International Business Machines Corporation | Dynamic updating of a word embedding model |
| US12026462B2 (en) | 2018-11-29 | 2024-07-02 | International Business Machines Corporation | Word embedding model parameter advisor |
| CN111523952B (en) * | 2019-01-17 | 2023-05-05 | 阿里巴巴集团控股有限公司 | Information extraction method and device, storage medium and processor |
| CN109783775B (en) * | 2019-01-18 | 2023-07-28 | 广东小天才科技有限公司 | Method and system for marking content of user corpus |
| US10937416B2 (en) * | 2019-02-01 | 2021-03-02 | International Business Machines Corporation | Cross-domain multi-task learning for text classification |
| US11003867B2 (en) * | 2019-03-04 | 2021-05-11 | Salesforce.Com, Inc. | Cross-lingual regularization for multilingual generalization |
| CN110046244B (en) * | 2019-04-24 | 2021-06-08 | 中国人民解放军国防科技大学 | An Answer Selection Method for Question Answering System |
| CN110110061B (en) * | 2019-04-26 | 2023-04-18 | 同济大学 | Low-resource language entity extraction method based on bilingual word vectors |
| CN110134962A (en) * | 2019-05-17 | 2019-08-16 | 中山大学 | A Cross-Language Plain Text Irony Recognition Method Based on Internal Attention |
| US11748571B1 (en) * | 2019-05-21 | 2023-09-05 | Educational Testing Service | Text segmentation with two-level transformer and auxiliary coherence modeling |
| US11227128B2 (en) * | 2019-06-07 | 2022-01-18 | Raytheon Bbn Technologies Corp. | Linguistically rich cross-lingual text event embeddings |
| CN112256664A (en) * | 2019-07-05 | 2021-01-22 | 阿里巴巴集团控股有限公司 | Cross-language data migration method and device |
| US10853580B1 (en) * | 2019-10-30 | 2020-12-01 | SparkCognition, Inc. | Generation of text classifier training data |
| CN110909551B (en) * | 2019-12-05 | 2023-10-27 | 北京知道创宇信息技术股份有限公司 | Language pre-training model updating method and device, electronic equipment and storage medium |
| US12293398B2 (en) * | 2020-03-23 | 2025-05-06 | Yahoo Assets Llc | Computerized system and method for applying transfer learning for generating a multi-variable based unified recommendation |
| CN111695361B (en) * | 2020-04-29 | 2024-11-26 | 平安科技(深圳)有限公司 | Method for constructing Chinese-English bilingual corpus and related equipment |
| US10817665B1 (en) * | 2020-05-08 | 2020-10-27 | Coupang Corp. | Systems and methods for word segmentation based on a competing neural character language model |
| US11797530B1 (en) * | 2020-06-15 | 2023-10-24 | Amazon Technologies, Inc. | Artificial intelligence system for translation-less similarity analysis in multi-language contexts |
| CN112182151B (en) * | 2020-09-23 | 2021-08-17 | 清华大学 | Multilingual-based reading comprehension task recognition method and device |
| DE102020212318A1 (en) * | 2020-09-30 | 2022-03-31 | Siemens Healthcare Gmbh | Case prioritization for a medical system |
| US11132988B1 (en) * | 2020-10-22 | 2021-09-28 | PolyAI Limited | Dialogue system, a dialogue method, and a method of training |
| US12153881B2 (en) | 2020-11-30 | 2024-11-26 | Oracle International Corporation | Keyword data augmentation tool for natural language processing |
| US12026468B2 (en) | 2020-11-30 | 2024-07-02 | Oracle International Corporation | Out-of-domain data augmentation for natural language processing |
| CN113220872B (en) * | 2021-02-08 | 2024-11-08 | 民生科技有限责任公司 | A document tag generation method, system and readable storage medium |
| US11790894B2 (en) * | 2021-03-15 | 2023-10-17 | Salesforce, Inc. | Machine learning based models for automatic conversations in online systems |
| CN113157865B (en) * | 2021-04-25 | 2023-06-23 | 平安科技(深圳)有限公司 | Cross-language word vector generation method and device, electronic equipment and storage medium |
| US20240177513A1 (en) * | 2022-11-29 | 2024-05-30 | Microsoft Technology Licensing, Llc | Language-agnostic ocr extraction |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9037464B1 (en) | 2013-01-15 | 2015-05-19 | Google Inc. | Computing numeric representations of words in a high-dimensional space |
-
2015
- 2015-09-24 US US14/863,996 patent/US9779085B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9037464B1 (en) | 2013-01-15 | 2015-05-19 | Google Inc. | Computing numeric representations of words in a high-dimensional space |
Non-Patent Citations (5)
| Title |
|---|
| A. Klementiev et al.; "Inducing Crosslingual Distributed Representations of Word"; 2012. |
| K. Hermann et al.; "Multilingual Distributed Representations without Word Alignment"; arXiv:1312.6173v4 [cs.CL] Mar. 20, 2014. |
| S. Chandar et al.; "An Autoencoder Approach to Learning Bilingual Word Representations"; arXiv:1402.1454v1 [cs.CL] Feb. 6, 2014. |
| T. Mikolov et al.; "Efficient Estimation of Wrod Representations in Vector Space"; arXiv:130.3781v3 [cs.CL] Sep. 7, 2013. |
| Y. Bengio et al.; "A Neural Probabilistic Language Model"; Journal of Machine Learning Research 3 (2003) 1137-1155; published Feb. 2003. |
Cited By (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11176327B2 (en) * | 2016-10-04 | 2021-11-16 | Fujitsu Limited | Information processing device, learning method, and storage medium |
| CN109871529A (en) * | 2017-12-04 | 2019-06-11 | 三星电子株式会社 | Language processing method and apparatus |
| US11017777B2 (en) * | 2017-12-04 | 2021-05-25 | Samsung Electronics Co., Ltd. | Language processing method and apparatus |
| CN109871529B (en) * | 2017-12-04 | 2023-10-31 | 三星电子株式会社 | Language processing methods and devices |
| US10579733B2 (en) | 2018-05-10 | 2020-03-03 | Google Llc | Identifying codemixed text |
| US11373006B2 (en) | 2018-05-30 | 2022-06-28 | Bank Of America Corporation | Processing system using natural language processing for performing dataset filtering and sanitization |
| US10769307B2 (en) | 2018-05-30 | 2020-09-08 | Bank Of America Corporation | Processing system using natural language processing for performing dataset filtering and sanitization |
| CN109299284A (en) * | 2018-08-31 | 2019-02-01 | 中国地质大学(武汉) | A Knowledge Graph Representation Learning Method Based on Structural Information and Text Description |
| US10936635B2 (en) | 2018-10-08 | 2021-03-02 | International Business Machines Corporation | Context-based generation of semantically-similar phrases |
| US10997977B2 (en) * | 2019-04-30 | 2021-05-04 | Sap Se | Hybrid NLP scenarios for mobile devices |
| US11227120B2 (en) * | 2019-05-02 | 2022-01-18 | King Fahd University Of Petroleum And Minerals | Open domain targeted sentiment classification using semisupervised dynamic generation of feature attributes |
| US11222176B2 (en) | 2019-05-24 | 2022-01-11 | International Business Machines Corporation | Method and system for language and domain acceleration with embedding evaluation |
| US11386276B2 (en) * | 2019-05-24 | 2022-07-12 | International Business Machines Corporation | Method and system for language and domain acceleration with embedding alignment |
| US11599768B2 (en) | 2019-07-18 | 2023-03-07 | International Business Machines Corporation | Cooperative neural network for recommending next user action |
| US11341339B1 (en) * | 2020-05-14 | 2022-05-24 | Amazon Technologies, Inc. | Confidence calibration for natural-language understanding models that provides optimal interpretability |
| US11393456B1 (en) * | 2020-06-26 | 2022-07-19 | Amazon Technologies, Inc. | Spoken language understanding system |
| US11875131B2 (en) | 2020-09-16 | 2024-01-16 | International Business Machines Corporation | Zero-shot cross-lingual transfer learning |
| US11741318B2 (en) | 2021-03-25 | 2023-08-29 | Nec Corporation | Open information extraction from low resource languages |
| US11853712B2 (en) | 2021-06-07 | 2023-12-26 | International Business Machines Corporation | Conversational AI with multi-lingual human chatlogs |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160350288A1 (en) | 2016-12-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9779085B2 (en) | Multilingual embeddings for natural language processing | |
| Ain et al. | Sentiment analysis using deep learning techniques: a review | |
| Al Khatib et al. | Cross-domain mining of argumentative text through distant supervision | |
| Wick et al. | Minimally-constrained multilingual embeddings via artificial code-switching | |
| Lasri et al. | Self-Attention-Based Bi-LSTM Model for Sentiment Analysis on Tweets about Distance Learning in Higher Education. | |
| Haque et al. | Opinion mining from bangla and phonetic bangla reviews using vectorization methods | |
| Assayed et al. | A chatbot intent classifier for supporting high school students | |
| Hindocha et al. | Short-text Semantic Similarity using GloVe word embedding | |
| Ramnarain-Seetohul et al. | Similarity measures in automated essay scoring systems: A ten-year review | |
| Joshi et al. | CISLR: corpus for Indian sign language recognition | |
| Bosco et al. | DeepEva: A deep neural network architecture for assessing sentence complexity in Italian and English languages | |
| Jian et al. | English text readability measurement based on convolutional neural network: A hybrid network model | |
| Huang et al. | Automatic Classroom Question Classification Based on Bloom's Taxonomy | |
| da Rocha et al. | A text as unique as a fingerprint: Text analysis and authorship recognition in a Virtual Learning Environment of the Unified Health System in Brazil | |
| Masri et al. | Transformer models in education: Summarizing science textbooks with AraBART, MT5, AraT5, and mBART | |
| Mittal et al. | Computerized evaluation of subjective answers using hybrid technique | |
| Shirsat et al. | Sentence level sentiment analysis from news articles and blogs using machine learning techniques | |
| Cuzzocrea et al. | Multi-class text complexity evaluation via deep neural networks | |
| Sarwar et al. | AGI-P: A gender identification framework for authorship analysis using customized fine-tuning of multilingual language model | |
| Voronov et al. | Forecasting popularity of news article by title analyzing with BN-LSTM network | |
| Ali et al. | Word embedding based new corpus for low-resourced language: Sindhi | |
| Kamble et al. | Learning to classify Marathi questions and identify answer type using machine learning technique | |
| Shah et al. | Automatic evaluation of free text answers: A review | |
| Kong et al. | Construction of microblog-specific chinese sentiment lexicon based on representation learning | |
| Belguith et al. | Social media sentiment classification for Tunisian dialect: a deep learning approach |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: ORACLE INTERNATIONAL CORPORATION, CALIFORNIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:WICK, MICHAEL LOUIS;KANANI, PALLIKA HARIDAS;POCOCK, ADAM CRAIG;SIGNING DATES FROM 20130922 TO 20150922;REEL/FRAME:036649/0129 |
|
| AS | Assignment |
Owner name: ORACLE INTERNATIONAL CORPORATION, CALIFORNIA Free format text: CORRECTIVE ASSIGNMENT TO CORRECT THE FIRST ASSIGNOR'S EXECUTION DATE PREVIOUSLY RECORDED AT REEL: 036649 FRAME: 0129. ASSIGNOR(S) HEREBY CONFIRMS THE ASSIGNMENT;ASSIGNORS:WICK, MICHAEL LOUIS;KANANI, PALLIKA HARIDAS;POCOCK, ADAM CRAIG;REEL/FRAME:036710/0676 Effective date: 20150922 |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| CC | Certificate of correction | ||
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 4TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1551); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 4 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 8TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1552); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 8 |